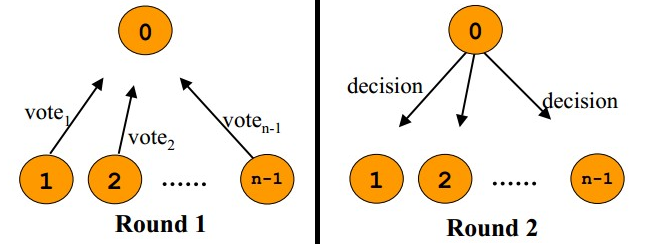
一个“蝇量级” C 语言协程库
这篇讲的是如何用不到100行代码在C语言里实现协程。作者从协程的背景讲起,对比了它和线程在“生产者-消费者”模型中的差异,指出C语言由于依赖栈帧实现函数调用,缺乏原生yield语义,直接实现对称协程比较麻烦。 文章核心介绍了开源库protothreads。这个库“蝇量级”到所有代码都在5个头文件里,每个协程只需2字节内存开销,非常适合资源敏感的嵌入式场景。作者还追溯了作者Adam Dunkels的其他知名作品,暗示其工业级可靠性。 实现的关键在于一个C语言“奇技淫巧”:利用switch-case语句的穿透特性和`__LINE__`宏,模拟了程序计数器的保存与恢复。通过将return语句嵌入case标签,并在函数入口用一个switch跳转到上次的挂起点,就用纯C语法实现了协程的挂起与恢复。文章最后展示了如何用宏封装出Begin/Yield/End这样的简洁接口,让开发者能写出类似Python生成器的代码结构。