二叉树迭代器算法
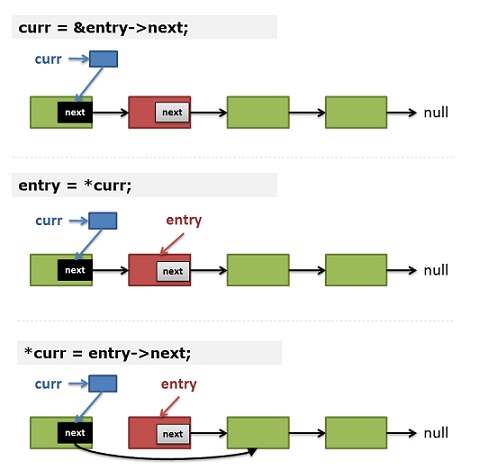
这篇文章探讨了如何为二叉树设计迭代器,从而将遍历算法与具体数据结构解耦,实现如通用求和函数这样的抽象操作。作者指出,直接转换递归遍历行不通,因为其依赖编译器管理的隐式调用栈。核心思路是通过显式栈结构来手动控制遍历流程。 文章详细展示了如何基于栈实现一个非递归的中序遍历,并将其封装为包含`next()`方法的迭代器。关键设计在于,迭代器的状态完全由栈的内容决定,每次调用`next()`对应一次栈操作。作者还澄清了一个常见误区:尽管单次`next()`调用可能涉及多次栈操作,但由于每个节点在整个迭代过程中仅入栈和出栈一次,因此总时间复杂度仍是线性的O(n),与递归遍历一致。 最后,文章简要对比了在支持`yield`语义的语言(如Python)中,一种更直观的生成器实现方式,并提示读者思考其背后的变换原理。