Linux文件系统基础之inode和dentry
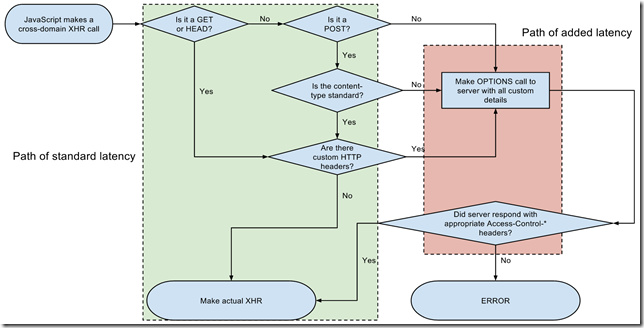
这篇讲的是Linux文件系统中两个最核心的元数据结构——inode和dentry,以及它们如何协同工作来构建我们熟悉的文件目录。 作者从虚拟文件系统VFS的抽象层入手,解释了为什么需要这些结构来统一管理底层不同的实体文件系统(如ext4)。文章指出,inode是内核中文件对象的唯一标识,它存储了权限、属组、数据块位置等所有静态元数据,但刻意不包含文件名。而文件名与inode的映射关系,则由目录项dentry在内存中动态建立和维护。 通过阅读文件路径时内核的解析过程,文章清晰地展示了dentry如何通过内存中的树状结构,高效地缓存和还原出文件系统的目录层次。这种设计将稳定的磁盘结构与灵活的内存缓存分离,是Linux文件系统高性能的关键。 理解了inode和dentry,文章最后点明,文件链接的奥秘也迎刃而解:软链接拥有独立的inode和内容,而硬链接仅仅是为同一个inode在目录项中新增了一条名字映射,并通过引用计数管理生命周期。整篇文章从底层原理出发,把看似复杂的文件系统机制拆解得条理分明。