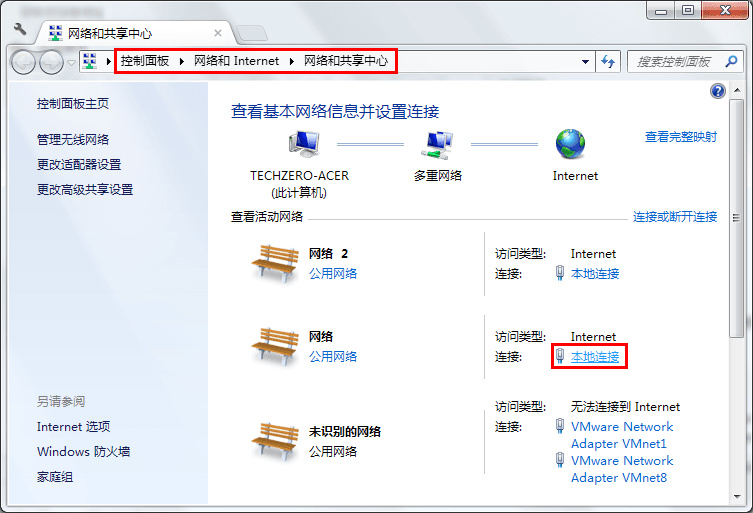
初入运维的小伙伴,别再问需不需要学Python了
这篇讲的是运维人员该不该学Python的老话题。作者从百度知道上一个常见的提问切入,观点很明确:掌握一门开发语言,尤其是Python,已经是高级运维工程师的必备技能。 文章认为,不会开发,就难以深入理解业务流程、优化性能,也无法在复杂场景(如数千台服务器)中实现真正的自动化运维,只能依赖通用工具或拼凑开源软件。而Python恰好能胜任,它既是强大的脚本语言,满足绝大部分自动化需求,又能用于开发后端的C/S架构和Web界面,让运维人员有能力构建自己的运维平台,从而体现核心价值。 作者也对比了其他语言。比如,PHP更专注于Web;Java显得臃肿;C++在运维场景中多数时候“是为了来装B的”;而Go语言虽新,但预计不会成为运维开发的主流。同时,针对“Python效率低”的说法,作者指出程序效率更取决于开发者本身,并以Tornado框架在Python下实现高并发作为例证,强调语言本身的影响只占一部分。 文章的核心结论是:别再纠结“需不需要学”,Python因其简洁、全面和生态优势,就是运维转向开发、提升竞争力的首选工具。