前端代码之丑(3):蛋疼的压缩式写法
这篇讲的是代码风格中的“压缩式写法”问题。作者从一年前自己的一段前端代码切入,那段代码在一个赋值语句中巧妙(或者说故意)地复合了多个操作,看起来紧凑而“高深”,实则让逻辑变得晦涩难懂。 文章的核心观点很明确:代码的简洁应服务于可读性,而非牺牲后者来追求表面的紧凑。作者通过一个清晰的前后对比展示了这一点。原先的“高深”写法试图在一行内完成对象属性的层层赋值与调用,而重构后的版本则拆解为三个直白的步骤——先赋值,再计算,最后缓存。后者虽然行数增加,但逻辑流一目了然,每一步都清晰表达了意图。 这对于日常开发是一个及时的提醒。代码是写给人看的,其次是给机器执行。过度追求技巧性的压缩,往往只会增加维护成本和理解门槛。真正的“简洁”是思路的清晰,而不是字符的堆砌。
前端代码之丑(2):丑陋的条件语句
这篇讲的是前端代码中那些让人心烦意乱的条件语句。作者从几个常见的代码“坏味道”出发:嵌套的 if-else 像迷宫一样难以维护,冗余的判断条件让逻辑模糊不清,还有过度分支导致代码急剧膨胀。 文章的核心是提供“解药”。它详细拆解了三种优雅的重构策略:用策略模式封装多变的逻辑分支,让主函数清晰如声明;用查表法(对象映射或 Map)替代冗长的 switch-case,将逻辑判断转化为数据查询;以及在复杂流程中引入状态机,明确状态转移,管理流程复杂度。 作者不仅展示了“怎么做”,更点明了“何时用”:策略模式适合行为频繁变化的场景,查表法对于数据驱动的逻辑尤其高效,而状态机则是管理多状态复杂流程的利器。它本质上是在讨论如何通过提升代码的可读性和可维护性,来对抗软件中不可避免的复杂度增长。
前端代码之丑(一):分支化技巧
这篇讲的是前端代码中常见的“分支化”臃肿问题。作者从一个实际项目中获取邮费目的地的代码片段出发,揭示了为适应不同页面编码(简体GB与繁体UTF-8)而产生的冗余分支。 文章的核心是逐步优化这段代码的思路。作者先指出可以移除用于“封存数据”的冗余闭包,改用更清晰的条件表达式。接着,发现两个分支函数仅查表不同,于是合并为单一函数,只在初始化时根据编码选择对应的映射表。更进一步,将两份大量重复的繁简数据表进行差异化处理,仅覆盖有差异的键值。 优化的最后,作者提到了“过犹不及”——将数据表再压缩为嵌套数组,虽然代码量最小,但增加了函数内部的复杂度,可读性反而下降。这提醒我们代码重构需在性能、可维护性和代码量之间做好权衡。通过这个案例,文章展示了如何通过几处简单的重构,让处理分支逻辑的代码变得更清晰、更健壮。
JavaScript 的异步测试
这篇讲的是如何有效测试 JavaScript 中的异步代码。异步操作因其非阻塞和时间不确定性,常常让测试变得棘手——回调可能未被正确调用、Promise 可能被意外忽略,导致测试通过但实际代码存在问题。 文章深入对比了处理异步测试的几种核心策略。它从最经典的回调与 `done` 参数讲起,分析了其局限性;接着重点介绍了利用 Promise 的 `return` 机制,让测试框架自动等待异步流程结束;最后则深入展示了现代的 `async/await` 语法如何让异步测试代码读起来像同步代码一样清晰直观。作者还具体提到了 `jest.useFakeTimers()` 这类工具在处理定时器相关异步逻辑时的妙用。 这篇内容的价值在于,它不是空谈概念,而是直接给出了从“能跑”到“可靠”的升级路径。读者能清楚看到不同方法的适用场景与最佳实践,比如何时该用 `async/await`,以及如何用工具控制时间流,从而写出既健壮又易维护的测试用例。
JavaScript 测试覆盖率检测工具
这篇讲的是如何在持续集成(CI)流水线中,利用工具自动化地确保测试对代码的有效覆盖。作者从“如何客观衡量测试质量”这一实际痛点出发,引入了JavaScript生态中广受欢迎的覆盖率检测工具Istanbul。 文章没有停留在工具介绍层面,而是深入到了具体的集成实践。它清晰地说明了使用Istanbul生成覆盖率报告的基本命令,并对比了lcov、html等不同报告格式的特点——lcov格式便于后续生成可视化图表或与SonarQube等平台集成,而html报告则方便开发者本地快速浏览未覆盖代码的详情。这种对比直接帮助读者根据自身团队的工作流做出选择。 更关键的是,文章指出了将覆盖率检测集成到CI流程中的两个关键点:一是配置合理的覆盖率阈值(如行覆盖率需达到80%),让检查结果成为流水线是否通过的硬性门禁;二是在大型项目中,可以配置“增量覆盖率”检测,只关注本次变更代码的覆盖情况,避免因历史代码覆盖率不足而阻碍新功能的交付。 最终,这篇文章提供的方案效果是明确的:它将原本模糊的“测试是否充分”问题,变成了一个可观测、可度量、可管控的自动化环节,帮助团队在快速迭代中守住质量底线,并推动建立“新代码必须有测试”的团队文化。
memoize 实现代码中的小陷阱
这篇讲的是一个在实现 memoize(记忆化)优化时极易被忽略的问题。许多开发者在封装缓存函数时,可能都以为只要实现“相同参数返回相同结果”就行,但实际代码里隐藏着不少陷阱。 文章作者从一个具体场景出发,揭示了 memoize 函数在实际使用中的几处典型漏洞。例如,如果缓存键仅仅使用参数的字符串或简单哈希值进行比较,那么当传入对象或数组等复杂引用类型时,哪怕内容相同但引用不同,也会导致缓存失效,从而产生预期外的重复计算。另一个常见的陷阱是,对于异步函数的缓存处理不当,可能引发竞态条件或回调错误。 更深入一层,文章还探讨了如何通过设计更健壮的键生成策略(如序列化+严格比较),以及利用闭包妥善管理缓存的作用域,来避免内存泄漏和污染全局状态。这些细节上的考量,直接决定了 memoize 工具是真正可靠的性能优化,还是埋下了隐蔽的 Bug。文章通过剖析这些“小陷阱”,提醒读者在追求代码效率的同时,务必对底层实现保持审慎的思考。
基于 SeaJS 模块化开发的一个实例
这篇文章围绕一个真实项目场景,讲解了如何使用 SeaJS 从零搭建模块化前端架构。作者从遇到的具体痛点切入:当项目规模扩大后,传统按文件目录组织代码的方式带来了变量污染、依赖混乱和维护困难等问题。为了解决这些难题,团队决定引入 SeaJS 进行重构。 文章详细展示了整个迁移过程的核心思路:首先,按照功能和业务逻辑,将庞大的 JavaScript 文件拆分成高内聚、低耦合的模块,每个模块只暴露一个接口。其次,利用 `define` 定义模块,`require` 引入依赖,`export` 输出内容,清晰地描述了模块间的依赖关系。文中还特别分享了处理模块加载顺序、配置路径别名以及整合第三方库(如 jQuery)的具体实践经验。 最终,通过这次改造,项目的代码结构变得清晰可维护,按需加载提升了页面性能,团队协作也因模块职责单一而更加顺畅。对于正在面临类似前端工程化问题的开发者而言,这篇文章提供了一个从理论到落地的完整参考案例。
CommonJS 的模块系统,AMD 和 Wrappings, 以及 RequireJS
这篇讲的是 JavaScript 模块化的演进与核心方案选择。作者从 CommonJS 在 Node.js 服务端的同步加载模型讲起,说明了它在浏览器端面临的两大挑战:同步阻塞和缺乏原生支持。随后引出了 AMD 规范,它采用“依赖前置、异步加载”的设计,正好解决了浏览器环境下的这两个痛点,而 RequireJS 正是这一规范的流行实现。 文章对比了两者的关键差异:CommonJS 更贴近开发者在服务端编码的直觉,模块即对象;而 AMD 为了浏览器性能,引入了回调函数和依赖声明。作者特别提到了“Wrappings”这一概念,即 RequireJS 如何通过包装机制将 CommonJS 风格的模块适配为 AMD 模块,让两套规范得以共存和迁移。 最后,文章指向了一个更现代的终点:ES Modules。它通过语言标准统一了前后端的模块化方案,使得 CommonJS 和 AMD 的许多设计成为了特定历史阶段的解决方案。对于仍在维护老项目或需要理解工具链历史的开发者来说,厘清这条脉络非常有价值。
从元编程到信息编程的遐想
这篇讲的是编程思想的一次深刻演进。作者从编程语言如何一步步获得“元能力”出发,最终引向一个更宏大的命题:我们或许正在经历从“元编程”到“信息编程”的范式转移。文章的核心观点非常明确——代码的本质是信息,因此整个编程学科的发展,可以被重新放置在信息论的框架下审视。 作者引用了香农、哥德尔、图灵等人的经典理论,提出了一种令人耳目一新的视角:传统的编程关注指令与计算,而“信息编程”则更关注信息的表达、变换与意义。这意味着,衡量代码优劣的标准可能不仅仅是执行效率,还包括信息的密度、结构的清晰度以及语义的可推导性。 这种遐想并非空谈。文章引导我们思考,当我们将一段代码看作待处理的信息熵时,设计模式、架构乃至编程语言本身,都可能需要被重新评估。对于开发者而言,这不仅是一次认知刷新,也可能预示着未来工具链和设计哲学的发展方向——让我们更自觉地去管理和优化代码背后流淌的“信息”。
JavaScript 压缩中的权衡
这篇文章从项目打包速度变慢的痛点切入,聚焦于JavaScript压缩环节常被忽略的“权衡”。作者对比了Terser、SWC和esbuild等主流工具在压缩速度、产物体积、语法支持及错误恢复能力上的差异。 文章指出,像Terser这样的传统工具压缩率高,但速度慢;而SWC和esbuild等基于Rust或Go的新工具,能在保持可观压缩率的同时将速度提升数十倍。关键差异在于,后者往往选择用部分压缩率换取极致的开发体验和构建效率。 作者进而分析了不同场景下的选择:在追求极致产物体积的线上环境,Terser可能仍是首选;但在大型项目或需要频繁编译的开发阶段,速度更快的工具能显著改善开发者工作流。文章还提到了一个有趣的发现:当代码因语法错误无法压缩时,部分新工具的错误恢复机制更为健壮。 最终,文章的核心观点是:没有“最好”的压缩工具,只有最适合项目当前阶段和团队需求的工具。这场关于速度、体积与功能的三角博弈,正是前端工程化中一个具体而微的缩影。
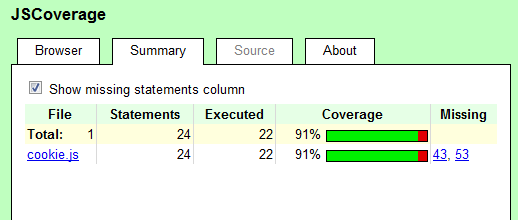
JSCoverage 的一个 Uncoverage
这篇讲的是代码覆盖率工具 JSCoverage 在实际使用中遇到的一个诡异问题。作者发现,即使手动执行了目标 JavaScript 代码,JSCoverage 的报告中依然显示这部分逻辑未被覆盖,产生了一个“伪阴性”结果。 问题的根源在于 JSCoverage 的检测机制与现代 JavaScript 引擎及模块加载方式存在兼容性问题。工具依赖于对脚本执行流程的特定监控,但当代码通过 ES6 模块或某些打包工具加载时,其默认的初始化和执行顺序会打乱 JSCoverage 的统计逻辑,导致覆盖率数据失真。 为了解决这个问题,作者深入分析了 JSCoverage 的源码和浏览器调试接口。最终的解决方案并非直接修改工具,而是通过调整测试环境的初始化脚本,在 JSCoverage 启动监控之前,提前触发了对目标代码路径的“预热”执行,从而巧妙地绕过了检测机制的盲区,获得了准确的覆盖率报告。这为处理类似工具兼容性问题提供了一个非常规的思路。
行进中的前端类库:KISSY
这篇文章从日常前端开发中恼人的浏览器兼容性问题切入,探讨了诞生于阿里巴巴的JavaScript类库KISSY。作者详细阐述了KISSY的设计原则,比如其“天下武功,唯快不破”的追求和高度模块化的架构理念,旨在为复杂Web应用提供高效、稳定的解决方案。 文章核心聚焦于KISSY的几大支柱:强大的UI组件库、完备的工具链以及贴近业务的框架特性。它不仅解决了基础交互问题,更通过KISSY Engine等底层优化,助力应对大规模电商场景下的性能挑战。此外,文中也介绍了围绕KISSY形成的开发规范、工具流以及活跃的社区生态,展现了一个类库如何从内部孵化走向开放,并持续演进以适应移动化、全栈化的新前端趋势。
a.x = a = { }, 深入理解赋值表达式
这篇文章从一个看似简单却暗藏玄机的JavaScript表达式 `a.x = a = { }` 出发,深入剖析了赋值运算符的执行机制与对象引用的核心逻辑。作者没有停留在表面语法,而是逐步拆解了该表达式从右到左的运算顺序、属性访问(`a.x`)与赋值操作的先后关系,以及由此导致的变量引用变化和最终对象结构的差异。 核心在于理解,虽然最终 `a` 和 `a.x` 都指向新创建的空对象 `{}`,但中间过程涉及旧对象 `a` 的属性被访问、然后整个引用被重新绑定到新对象这一系列动作。文章对比了直接连等赋值 `a = {}` 与这种复合表达式的区别,清晰揭示了后者可能引发的意外副作用,尤其是在旧对象 `a` 上下文仍然被其他代码依赖时。 这种对基础语言特性的深度剖析,不仅有助于理解看似晦涩的代码,更能从根本上培养开发者对JavaScript中引用传递和表达式求值顺序的敏感度,避免在复杂业务逻辑中踩坑。
用 CSS3 Transitions 实现动画
这篇讲的是作者从一个常见的开发需求出发——“如何为元素添加平滑的交互动画”,系统梳理了使用 CSS3 Transitions 来实现的完整路径。 文章的核心观点很明确:在众多动画实现方案中,CSS3 Transitions 是针对“状态间平滑过渡”这一特定场景的绝佳选择,它相比 JavaScript 动画,在性能、代码简洁度和开发体验上有着显著优势。作者将两者进行了关键差异对比:CSS3 Transitions 由浏览器引擎优化,通常能利用 GPU 加速,性能开销更小;其代码是声明式的,只需定义起始与结束状态,中间的插值过程完全交由浏览器处理,这使得逻辑非常清晰。 为了让读者有更具体的感知,文章深入拆解了几个核心应用场景。例如,最常见的按钮悬停反馈,只需几行 transition 属性就能定义颜色、尺寸或阴影的持续时间与缓动函数;还有列表项的显隐交错动画、卡片展开/收起的交互效果等。作者特别指出了 `transition-timing-function`(如 `ease-out`)对于动画是否“自然”的关键作用,这是一个常被忽略的细节。 整体而言,这篇内容没有停留在“什么是 Transitions”的语法介绍,而是聚焦于“什么时候用、怎么用得好”的实战决策,为前端开发者提供了一个清晰、可落地的轻量级动画实现指南。
细说 expando 的来源
这篇讲的是 JavaScript 中一个很少被正式提及、却又无处不在的术语——expando 的身世。作者从大家耳熟能详的“不要随意给 DOM 元素添加 expando 属性”这条忠告切入,试图追溯这个词的源头。 文章梳理了 expando 与早期 Internet Explorer 浏览器的渊源。它最初是 IE 提供的一种非标准方式,允许开发者通过简单的赋值为任何 JavaScript 对象(包括 DOM 元素)动态添加任意属性,这些属性会直接“扩展”该对象。在标准 DOM 属性方法普及前,这曾是实现某些交互效果的常见手段。 关键在于,这些“扩展”属性不会出现在标准的 `hasOwnProperty` 检查中,且可能在 DOM 序列化或垃圾回收时引发意料之外的副作用,这也是那条“忠告”的由来。随着 Web 标准演进,现代浏览器已能良好处理这类情况,但了解其历史能帮助我们更深刻地理解 JavaScript 对象模型的动态性以及早期浏览器兼容性问题的缩影。 对于前端开发者而言,明白 expando 的来龙去脉,不仅能解开许多历史代码的疑惑,也能更审慎地对待“动态添加属性”这一模式,知晓其背后的潜在影响。
前端性能优化的方向
这篇文章点出了一个常被忽略的起点:前端性能优化,根基其实在“内容”。作者开篇就抛出一个鲜明的观点——对整体性能至关重要的内容质量,恰恰是前端工程师无法直接掌控的,而只能去“建议”。这立刻拉高了讨论的维度。 它没有停留在代码层面的优化技巧,而是引导读者将视野拓宽到整个协作链条。文章探讨了如何从产品经理的需求、运营的策略到技术侧的实现细节,构建一个围绕内容的性能意识共同体。这种视角的转换,或许比某个具体的加载提速方案更有长远价值。 如果你正埋首于构建性能指标或优化渲染流水线,这篇文章提供了一个反思的机会:我们努力优化的“管道”里,流动的“水”本身质量如何?它鼓励前端开发者主动沟通,将性能优化提升到产品整体体验的层面来思考。
优雅兼容之理想与现实
这篇文章探讨了Web开发中一个经典而棘手的命题:如何在追求CSS代码优雅与现代标准的同时,妥善处理不同浏览器环境下的现实兼容性问题。 作者从实际项目经验出发,深入剖析了“理想”的CSS标准写法(如Flexbox、Grid等现代布局方案)在“现实”的浏览器生态(尤其是遗留环境)中可能遭遇的种种困境。文章并未止步于罗列兼容性差异,而是进一步对比了多种应对策略的得失——比如是采用特征检测逐步增强,还是通过预处理器编写兼容代码;是拥抱优雅降级,还是坚持渐进增强。关键差异点在于,每种方案在开发效率、代码可维护性以及最终用户体验之间,做出了不同的权衡与取舍。 对于前端开发者而言,这篇文章的价值在于它提供了一种平衡的视角:既不盲目追求不切实际的“纯标准”,也不因噎废食退回古老的布局时代。它引导读者根据项目的具体技术栈、浏览器支持要求和长期维护成本,来制定最合适的兼容策略,从而在理想与现实之间找到那个优雅的平衡点。
Google Docs Ctrl + C 技术浅析
这篇讲的是,当在 Google Docs 中打开 PDF 并复制文本时,那看似简单的 Ctrl+C 背后,其实是一套相当复杂的实现。作者深入分析了浏览器中剪贴板事件的拦截与处理机制,揭示了 Google Docs 如何巧妙地利用这个接口来捕获用户的选择操作。 具体来说,文章聚焦于浏览器环境下的技术栈。它剖析了文档应用如何通过监听 `copy` 事件,来获取用户选中的文本内容,并可能进行二次处理(例如格式转换或注入特定标识符),以确保复制到系统剪贴板的数据能被后续操作精准识别。这其中涉及到对浏览器默认行为的干预、事件对象的封装细节,以及跨应用(从Web应用到操作系统剪贴板)的数据传输逻辑。 分析这个过程,不仅让我们看到一个常见功能背后的工程复杂度,也对理解 Web 剪贴板 API 的实际应用场景和限制有直观认识。对于前端开发者而言,其中关于事件控制的技巧,也值得在处理类似富文本或跨域数据交互时参考借鉴。
用 JS 枚举质数
这篇讲的是用JavaScript枚举质数的几种常见
KISSY 近期更新 & 设计思路讨论
这篇讲的是知名前端框架 KISSY 的一次“开源”讨论。作者将原本属于团队内部的邮件交流——内容涉及近期更新和核心设计思路——有意识地向所有关注者开放,希望听到更多外部的声音。 文章的核心价值在于其“透明度”。它没有给出既定结论,而是呈现了设计过程中的权衡与思考。例如,在讨论近期更新时,团队可能会探讨某个新特性(如模块化增强或性能优化)的初衷、实现难点以及与旧方案的取舍。而在设计思路层面,则可能涉及对组件化规范、API 风格或未来演进方向的开放性辩论。 这种分享方式的启发在于:技术决策并非在真空中产生。将思考过程与社区共享,不仅能汇聚更广泛的智慧来验证或挑战原有假设,也让使用者能更深刻地理解框架的演变逻辑。对于正在使用或评估 KISSY 的开发者而言,这无疑提供了一个窥见其内部演进、并直接参与塑造未来的宝贵窗口。