为什么C语言需要函数声明
这篇讲的是作者从同事遇到的一个诡异bug出发,揭示了C语言中“函数声明”为何不可或缺。同事的代码中,一个返回double的函数,在函数内部打印的值和外部接收到的值差异巨大。通过反汇编,作者发现了关键线索:编译器生成了一条将整型转换为双精度浮点的指令(cvtsi2sd)。 根因在于,当函数在别的源文件中定义,而调用方没有其声明时,编译器在编译阶段并不知道该函数的真实面貌。它会默认函数返回整型(放入eax寄存器)。由于调用方实际期望一个浮点值(应放入xmm0寄存器),编译器就在调用后强行做了一次类型转换,从而导致了值的错误。问题不仅限于返回值,未声明的函数参数也会导致编译器忽略类型检查,可能引发更隐蔽的栈或寄存器传参错误。 作者指出,现代编译器如GCC能通过-Wimplicit-function-declaration选项对此发出警告。根本的解决之道是养成良好习惯,开启-Wall选项,并确保在使用任何外部函数前都进行正确声明。
由原子操作引起的关于Cache的讨论
这篇讲的是一个实际的性能排查案例:在MPI集群上,当PLDA算法与MLR或PLSA同时运行时,后者效率会大幅下降。问题最初被指向PLDA中频繁使用的原子操作——`lock incl`指令。用户担心这个`lock`前缀会锁死内存总线,拖垮整台机器。 作者澄清了一个常见误解:在现代CPU(如Nehalem架构)上,`lock`前缀在绝大多数情况下并不会锁总线,而是通过一种被称为“cache lock”的机制,在cache line级别实现原子性。他结合Intel手册与同行讨论,进一步指出硬件上并不存在真正的“cache lock”,而是依赖MESI这类缓存一致性协议来保证原子性。例如,带有写意图的原子读操作会触发RFO,导致其他核心的相关缓存失效,但这并不等同于锁住整个总线。 基于这个理解,问题的优化方向就清晰了:为了最小化不同任务之间的干扰,可以通过cgroup将它们绑定到不同的物理CPU上,从而隔离L1缓存。最终,作者通过共享内存和原子操作,替代了原先为每个线程分配独立大内存的做法,得以在限制内存占用的同时,启动更多线程将CPU利用满,反而获得了整体性能的提升。 对读者而言,这是一次从具体现象深入到底层硬件原理(CPU缓存一致性协议)的实用分析,有助于理解并发编程中原子操作的真实开销与优化思路。
记一下那些伪随机数生成函数
这篇讲的是一个在多线程环境下由伪随机数生成函数引发的性能“血案”。作者在使用100M数据跑LDA算法时,发现多线程迭代反而比单线程慢了数倍,且CPU大量时间耗在系统空间。排查后发现,罪魁祸首正是代码中调用的random()函数。 原来,glibc中的random()和rand()虽然是线程安全的,但其内部实现(加了一把全局锁)导致它们是不可重入的。在多线程竞争同一把锁时,性能便一落千丈。文章进而对比了rand_r()等可重入函数的实现,指出其算法较弱;而drand48系列函数则提供了更优的、基于独立状态数组的可重入版本(如erand48_r())。作者清晰地梳理了这些函数族的内在区别与适用场景:若需多线程高性能计算,必须使用能维护线程本地状态的可重入版本。 文章从具体坑点出发,剖析了glibc源码实现,最终落到了对随机数函数选型的实用建议上,对理解并发编程中的隐形陷阱很有启发。
Sheepdog块设备驱动死锁的问题
这篇讲的是一个在压测Sheepdog块设备驱动时遇到的诡异死锁问题。作者在将Sheepdog虚拟磁盘挂载为宿主机本地块设备,并运行QEMU虚拟机进行高强度IO写入后,偶尔会触发系统卡死,甚至基础命令如`ps -ef`也会被阻塞。 通过`sysrq-trigger`工具抓取进程状态,作者定位到两个关键进程:一个是Sheepdog服务进程(sheep),正卡在内核的内存回收路径`shrink_page_list`上;另一个是QEMU进程,也处于不可中断的D状态。两者形成了一个经典的资源依赖环。 死锁的根因在于内存与IO的相互等待:sheep进程因内存不足,试图回收一个内存页,而该页恰好被QEMU的页缓存占用。QEMU若要释放此页,需将其回写到作为后端存储的Sheepdog设备上。但这个回写请求又必须通过本机的Sheepdog驱动发送给已经卡住的sheep进程处理。于是,sheep等待页释放,QEMU等待sheep响应,形成了无法打破的死锁。 这个问题并非编码缺陷,而是在特定部署架构(本地驱动与存储服务同机运行)下难以避免的竞争条件。作者最终得出结论,解决之道是将存储客户端驱动与存储服务节点分离部署,避免资源回收路径上的循环依赖。
BLCR(Berkeley Lab Checkpoint/Restart)介绍及Checkpoint架构剖析
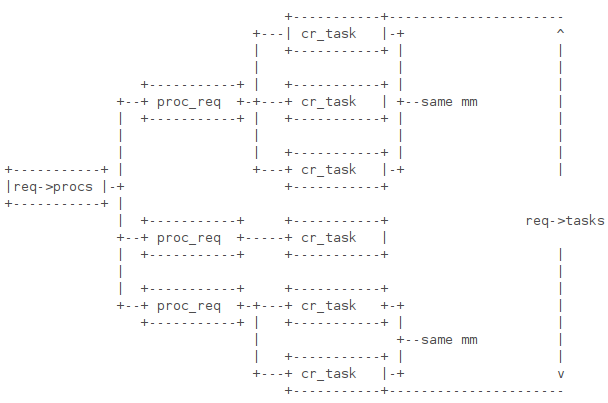
这篇讲的是进程检查点(Checkpoint)工具BLCR的核心架构剖析。作者从`cr_checkpoint`命令的用法出发,深入讲解了BLCR如何通过特定信号(64号实时信号)与内核模块协作,来实现对进程状态的“快照”保存。 文章重点剖析了用户态工具与内核模块通过`/proc`文件系统交互的机制。核心在于,BLCR需要为目标进程预先注册一个专用的信号处理函数。为此,它设计了两种等效的接入方式:一种是使用`cr_run`脚本启动程序,通过`LD_PRELOAD`预加载`libcr_run.so`库;另一种是在编译时直接链接`libcr`库。文章进而深入内核,解析了检查点请求(`cr_chkpt_req`)的构建过程,以及内核如何通过创建任务对象和进程请求对象来跟踪目标进程树,并最终完成内存的转储。 最巧妙的是,文章对比了两种接入方式在底层实现上的微妙差异:链接`libcr.so`的程序在信号处理函数中会通过两次`ioctl`调用来完成操作并通知完成;而通过`cr_run`启动的程序则使用汇编实现的信号处理函数,一次性完成转储并依赖一个特殊标志(`_CR_CHECKPOINT_STUB`)在内核侧直接触发完成流程。这种对源码细节的深挖,揭示了BLCR在兼容性和设计灵活性上的考量。
VIM复制粘贴的那些事
这篇讲的是作者从gvim切换到命令行vim后,遇到的一个核心痛点:与系统剪贴板之间的复制粘贴失灵。他发现,虽然粘贴操作勉强可用但格式容易混乱,而将vim里的内容复制到其他程序却似乎完全行不通。 这个问题的根因其实涉及不同程序间剪贴板访问权限的机制差异,以及vim自身对寄存器的设计。作者经过一番折腾,最终找到了一个能实现“向外复制”的方法,尽管他自己形容这个办法“比较蹩脚”。 文章并没有停留在抱怨问题,而是真实记录了一位普通开发者的踩坑与排查过程,对于同样被这个“经典老问题”困扰的vim用户来说,其中的思路和最终的发现可能直接提供一种解决问题的线索。
Apache MPM Prefork设计方法浅析
这篇讲的是 Apache 服务器里一种经典的进程模型——Prefork 的设计原理。作者从 Apache 的 MPM(多处理模块)机制入手,深入剖析了 Prefork 模型的代码实现。 Prefork 的核心思路是在服务器启动时预先 fork 出一批子进程,组成一个进程池来等待和处理请求。文章细致分析了它如何管理这些进程:主进程负责监听和创建,而多个子进程则并发地接受并处理客户端连接。这种设计让每个请求都由独立的进程处理,进程之间完全隔离,一个请求出错不会直接影响其他。 作者也对比了 Prefork 与其他模型(如 Worker)的关键差异。Prefork 的优势在于稳定性和隔离性,特别适合需要兼容老模块或运行 PHP 等非线程安全代码的场景。但它的缺点也很明显:每个进程都占用独立内存,在高并发下资源消耗会比较大。文章通过代码层面的解读,展示了这种“一进程一请求”的经典设计是如何在平衡资源与稳定性之间做出取舍的。
Memcached的线程模型及状态机
这篇讲的是 Memcached 内部是如何高效管理并发请求的。作者从对 Memcached 的好奇出发——这款广泛使用的分布式缓存,其核心源代码只有约10K行,但实现却非常精巧。他重点剖析了 Memcached-1.4.7 版本的线程模型与状态机设计。 文章的核心思路是,Memcached 通过“主线程监听 + 多个工作线程处理”的模型来分工。主线程负责接受连接,然后将这些连接分发给不同的工作线程。每个工作线程内部,则通过一个清晰的状态机来管理一个网络连接的完整生命周期:从等待数据、读取请求、处理命令,到最后写回响应。这种设计巧妙地避免了不同线程对同一连接资源的锁竞争,让每个线程都能独立、流畅地处理自己负责的连接。 通过源码分析,作者揭示了 Memcached 如何用相对简洁的代码实现了高并发的服务。状态机让请求的处理流程变得有序且易于维护,而线程模型则确保了多核CPU下的性能。对于想了解高性能服务端设计细节的开发者来说,这次源码之旅能帮助理解 Memcached 背后那些“看不见”却至关重要的架构决策。
Memcached内存管理机制浅析
作者从 Memcached 源码入手,深入剖析了其内存管理的核心机制——Slab Allocation。不同于简单介绍,文章直接切入 Memcached 为解决内存碎片化问题而设计的这套高效方案。 核心思路是将内存预先分割成固定大小的内存块(Slab Class),每个 Slab 内部再细分为相同尺寸的 Chunk。当数据存入时,Memcached 会根据数据大小找到最匹配的 Slab Class,从中分配一个 Chunk。这种“分类定长”的分配方式,极大减少了内存碎片,提升了分配与回收的效率。文章还具体分析了 Slab 的扩展策略以及内存池(Memcached_arena)在其中的作用。 通过源码级解读,文章清晰地展现了 Memcached 如何用看似简单的“空间换时间”策略,实现了高性能、低碎片化的内存管理,揭示了其在实际高并发场景下能够保持稳定高效的底层原因。
Redis的事件循环与定时器模型
这篇讲的是Redis单进程单线程模型背后的深层设计考量。作者从翻阅Redis源码出发,注意到一个“诧异”之处:这款高性能KV数据库并未采用常见的并发模型(如多进程/多线程),而是选择了看似“低效”的单线程架构。 文章的核心在于剖析这一设计选择的巧妙之处。作者推断,Redis的业务场景(快速内存操作、复杂数据结构)使得程序的可并行化程度并不高,顺序计算反而更优。单线程模型不仅省去了多线程同步、锁竞争以及维护线程池的开销,还简化了实现,这恰恰是Redis能够实现极高吞吐量与极低延迟的关键。这种对性能瓶颈的精准判断和取舍,值得后端开发者深入思考。 摘要自然收束,点明了文章对理解高性能服务设计的启发价值。
Tweets2PDF开发手记
这篇讲的是作者从个人需求出发,快速用Python实现了一个Twitter推文备份工具的故事。 作者一直想学Python,恰好临近过年有了空闲,萌生了将自己Twitter上的推文导出保存为PDF的想法。想到就做,他决定借此机会动手实践,对比了C和Python的开发效率后,果断选择了后者以缩短开发周期。经过几天的集中“折腾”,一个名为Tweets2PDF的小工具便诞生了,能够完成推文的获取与PDF格式导出。 文章记录了从灵感到落地的完整过程。其中核心的决策点在于技术选型:在时间有限的前提下,Python显著的开发效率优势,让作者得以快速实现功能原型。这体现了一种务实的工程思路——优先让想法变成可用的产品。工具虽小,却完整覆盖了数据获取、处理和格式化的关键环节,对于想学习快速原型开发或了解Twitter API初步应用的读者来说,这个简短的实践记录提供了清晰的路径参考。
浅析Linux Kernel 哈希路由表实现(二)
这篇讲的是Linux内核在发送数据包时,如何通过一个清晰的函数调用链找到路由的实现细节。作者从外层函数ip_route_output_key()出发,一步步追踪到最终的执行者__ip_route_output_key()。 核心焦点就集中在__ip_route_output_key()这个函数上。它是内核路由查找的真正引擎,负责根据目标地址、源地址等关键信息,在哈希路由表中高效地匹配出最佳路由项。文章没有停留在概念层面,而是直接潜入内核源码,剖析这个函数如何处理不同的查找场景,比如它是如何利用路由缓存加速,以及在复杂情况下如何进行精确的匹配与回溯。 通过这样的分析,读者能清晰地看到内核网络栈为了兼顾性能与准确性,在路由查找路径上做出的精巧设计。这种对底层实现逻辑的拆解,对于理解数据包的旅程和网络性能优化都很有启发。
浅析Linux Kernel 哈希路由表实现(一)
这篇讲的是 Linux 内核如何高效管理和查找海量路由条目的核心机制——哈希路由表。 作者从网络子系统中的路由表基础概念出发,深入剖析了内核采用哈希表作为底层数据结构的具体实现。文章没有停留在理论,而是紧扣内核源码,拆解了关键数据结构的设计,比如哈希桶的组织方式、路由条目节点的定义,以及如何通过特定的哈希函数(如 `fib_hash`)将 IP 目标地址映射到桶中。 其巧妙之处在于,内核并非简单套用通用哈希表,而是针对路由查找“精确匹配”的特性和高并发场景做了专门优化。例如,通过合理的哈希函数减少冲突,并结合锁机制(如 RCU)来平衡查找性能与并发更新时的开销。文章分析了这些设计如何共同作用,使得即使面对数十万条路由规则,内核依然能快速完成查找,这是保障网络设备转发性能的关键。 作者通过解读源码,揭示了内核开发者在性能与复杂性之间所做的权衡,让读者能理解这一基础设施背后的工程智慧。
浅析Linux Kernel中的那些链表
这篇讲的是Linux内核中链表的实现。作者从内核开发者最熟悉的链表结构切入,指出它与数据结构教材中的标准链表有着本质区别。 文章的核心在于剖析内核链表的巧妙设计。它并非传统意义上“节点包含数据”,而是采用侵入式设计:链表节点(`list_head`)被嵌入到你想要管理的数据结构本身中。这样,一套通用的链表操作代码就能管理任意类型的数据,无需为每种数据重写实现。 作者详细对比了侵入式链表与非侵入式链表的差异。传统链表需要为数据分配单独的节点内存,而内核链表将节点与数据合为一体,在内存管理上更为高效和灵活。这种设计使得通过一个数据结构中的链表节点,可以反向定位到包含它的整个结构体,这是理解后续很多内核数据结构(如进程队列)的关键。 文章最后可能总结,这种设计牺牲了一点点直观性,但换来了极大的通用性、性能和内存效率,是内核编程中“空间与时间”、“通用与专用”权衡的经典范例。对于想深入理解内核源码的开发者来说,厘清这个基础结构至关重要。
浅析linux kernel network之socket创建
作者从Linux内核网络子系统的一个基础但关键的环节——socket对象的创建——出发,梳理了用户空间系统调用到内核数据结构初始化的完整路径。这篇文章并非泛泛而谈,而是聚焦于`sys_socket`入口之后,内核如何通过socket操作集(`proto_ops`)找到对应的协议族(如IPv4),再进一步匹配具体的传输层协议(如TCP)并创建核心的`sock`对象。 其精妙之处在于揭示了这一过程清晰的分层与解耦:从通用的socket层,到特定的协议族层,再到具体的传输层,每一步都通过函数指针表进行动态绑定。作者对`sock`结构体初始化的分析,尤其是协议操作集(`sk_prot`)与socket操作集如何被赋值和关联,让读者能直观理解内核如何为后续的数据收发构建好必要的“骨架”。 对于想了解网络协议栈内部构造的读者,这篇文章提供了一个扎实的起点,它将抽象的“创建连接”动作,拆解成了内核中一系列具体而有序的函数调用与结构体填充,为后续探索数据包的处理流程打下了基础。
Apache基础数据结构(tables)代码浅析
这篇讲的是Apache HTTP Server(httpd)中一个基础且关键的数据结构——`tables`。在众多轻量级Web服务器涌现的今天,这篇分析直接深入到这位“老兵”最核心的C语言源码之中。 作者从`tables`如何存储和管理键值对(如HTTP头、环境变量)入手,剖析了其内部实现。文章不仅展示了它用数组和哈希表结合的灵活内存布局,还特别点出了其内存预分配、按需增长的“惰性”策略,以及在查找、插入、迭代操作上如何权衡性能与内存占用。 这些看似朴素的设计,在并发处理海量请求时,恰恰是高效且稳定的基石。对于想理解高性能C项目如何设计基础组件、或对Apache内部机制感兴趣的读者,这篇文章提供了一个很好的微观窗口,其思路对优化其他C语言项目的数据容器也有借鉴意义。
libofetion demo以及纯命令行飞信
这篇讲的是作者如何响应用户需求,为 libofetion 编写演示程序并优化其 API 接口。作者从用户对纯命令行飞信版本和 libofetion demo 的持续呼吁出发,利用周末时间完成了相关代码。 核心改进集中在让 libofetion 的 API 更符合通用库的设计习惯,使其对第三方开发者更加友好。不过,作者也坦言,由于最初并未将 libofetion 作为标准库来设计,其中仍存在一些对新开发者而言不易理解的实现细节。 除了演示 demo,文章也展示了纯命令行版本飞信的实现思路。作者在文末提到,随着实验室项目和论文工作重新提上日程,对飞信的个人开发将暂时告一段落。整篇文章清晰呈现了从需求到实现的技术路径,以及开源项目在个人精力分配下的一个自然节点。