为什么我认为架构师需要坚持写代码?
这篇文章从近期技术圈关于“架构师应具备哪些能力”的讨论切入,剖析了架构师的两种类型:一种擅长任务分解、资源整合与项目交付,本质上是在既定框架内填充内容;另一种则具备“技术杠杆”能力,能借助代码与技术方案大幅提升效率或创造新可能,例如通过算法改进用户体验。作者的核心观点是,后者才是能驱动技术变革的关键角色,而这样的架构师必须坚持写代码。 文章进一步指出,不写代码的架构师容易沦为“填格子的人”,难以深入理解技术细节,更无法运用技术力量放大业务价值。在评估架构师能力时,作者提到一种实用的面试方法:让候选人先完成小型代码编写测试,以此作为能力基线,再讨论架构设计。这能有效区分出真正有一线编码经验、能用技术解决问题的候选人,而非仅擅长沟通与流程管理的人。 整体来看,作者强调架构师的价值不仅在于设计蓝图,更在于通过亲手实践保持技术嗅觉,从而找到以技术杠杆撬动更大成果的机会。这对团队如何定义架构师角色、进行人才评估,提供了务实的视角。
《火星救援》中你应该知道的5个高可用系统故障恢复原则
这篇文章从电影《火星救援》出发,将主角马克·沃特尼的火星生存挑战,与互联网高可用系统的故障恢复实践做了精彩类比,提炼出了五条关键原则。 作者指出,故障发生时应秉持信息透明原则,及时向内部与外部同步状态,这比隐瞒问题更能赢得理解与支援。面对紧迫的恢复时限,技术负责人需在信息不全的情况下快速决策。在解决过程中,既要鼓励工程师发挥主观能动性积极尝试,也要善于利用系统预留的“救生锤”——比如那些99.9%时间不用的功能开关或旧接口。最后,当常规手段失效时,可能需要像电影里抛弃所有负重一样,采取一些简单粗暴但有效的方法来快速恢复服务,事后再进行数据修复。 文章没有停留在抽象理论,而是紧扣电影情节与技术场景的对应点,比如NASA的新闻发布会对应故障公告,探路者号对应遗留系统,让这些工程原则变得生动可感。文末那个马克在地球喝咖啡的比喻,也巧妙点出了运维人员平凡日常中的珍贵。

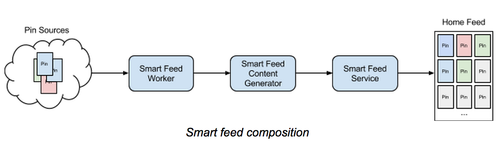
Pinterest的Feed架构与算法
这篇讲的是Pinterest如何将首页Feed流从简单的时序排列,升级为高性能、高可用的个性化推荐系统。随着流量增大,约1/3的访问指向Feed页,工程师面临的核心挑战是:如何在保证99.99%可用性的前提下,为每个用户动态生成个性化的高质量内容。 核心方案是一个分层的“Smart Feed”架构。它不再按时间排序,而是按权重优先展示。系统由三个关键服务构成:Feed Worker负责接收新内容并为每个用户独立计算权重,放入优先级队列;Feed Content Generator根据队列生成新的、按优先级排序的Pin流;Smart Feed Service则负责整合新内容与历史快照,确保即使在新内容生成服务异常时,用户也能快速看到历史列表,实现优雅降级。 存储层的设计尤为巧妙。面对海量数据和高写入QPS,Pinterest采用了双HBase集群方案。主集群处理写入,通过异步任务将数据同步到备用集群。读取时则优先从轻量的“物化存储”集群获取历史列表,再与主集群的新内容合并。这一设计不仅优化了读写延迟,更通过跨可用区的备份,将整体可用性提升至99.99%以上。
微博分布式存储作业实现方法
这篇讲的是微博如何在单表60亿条数据的极端场景下,设计分布式存储系统。作者从新兵训练营的实际练习题出发,拆解了社交场景下“查最近微博”和“翻阅用户全部微博”两大核心访问需求,以及由此带来的扩展性、成本与高可用设计挑战。 文章详细讨论了基于用户ID(UID)的范围分片与哈希分片策略,并对比了各自的利弊。重点分享了如何通过“冷热数据分离”来平衡成本与性能:近期数据(如最近10天)采用UID结合权重哈希的方式,均匀分散高并发读取压力;历史数据则按时间维度(如半年)分库,便于管理与冷存储。针对复杂的分页跳转查询,还提出了增加二级索引表等具体的索引设计思路。 文中展示了多个投稿案例,包括一种通过ZooKeeper动态调整分片策略、以灵活应对流量突变的方案。整体思路清晰,从约束条件到具体技术选型层层递进,为处理超大规模社交数据的存储与查询提供了切实可行的架构参考。

程序员技术晋升非正式攻略
这是一篇**事件复盘/观点类**的文章,围绕程序员在大厂技术晋升体系中的困惑与准备,分享了作者的实践经验与核心观点。 作者以腾讯等大厂的职级体系为背景,系统解答了从材料准备、评审标准到心态调整的系列问题。文章指出,晋升材料的核心是证明自己的能力达到了下一级别的要求,需重点展示项目中的技术贡献与影响力。评审过程更看重技术能力而非单纯努力,且高阶晋升通常由专家小组负责,直接上级的影响力随职级升高而减弱。 文章给出了许多具体建议:面对评委质疑时,应坦然接受不足而非强行辩解;要主动展示对团队的指导与影响,以及超出岗位要求的贡献;展示能力不求华丽,但求逻辑清晰。最后,作者强调晋升是“僧多粥少的游戏”,评审存在局限性,通过与否不应定义个人价值。真正的关键在于调整心态,将精力投入能产生实际成果和长期影响力的事情上,而非将晋升本身作为终极目标。
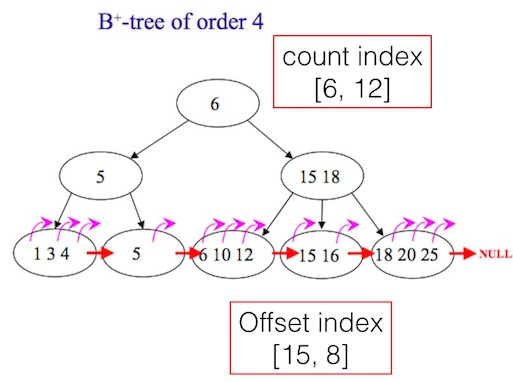
为什么超长列表数据的翻页技术实现复杂(二)
这篇讲的是如何为超长列表设计高效的翻页方案。作者延续上篇对问题的探讨,以新浪评论系统的经典演进为引子,剖析了从缓存翻页到自定义文件索引等方案的演进与局限,最终聚焦于一个核心矛盾:MySQL常用的B-TREE索引结构,虽擅长点查,却天生不利于范围查询(Range Scan),导致翻页性能低下。 为此,文章提出了两种实用的二级索引思路。一是“Count index”,通过额外记录每个非叶子节点下的条目总数,实现对任意offset位置的快速定位。二是“Offset index”,在应用层(如Redis)缓存部分offset与对应ID的映射关系,当需要定位某个offset时,可以从最近的缓存点开始扫描。 文章进一步给出了这两种思路在MySQL和Redis中的具体实现示例。比如Count index可以建一张辅助表按月份记录各用户的评论计数,而Offset index则在用户翻页时动态缓存到Redis,并在数据变更时及时清理。这两种方法都已在实际生产环境中得到验证,为解决超长列表的翻页难题提供了清晰且可落地的技术路径。
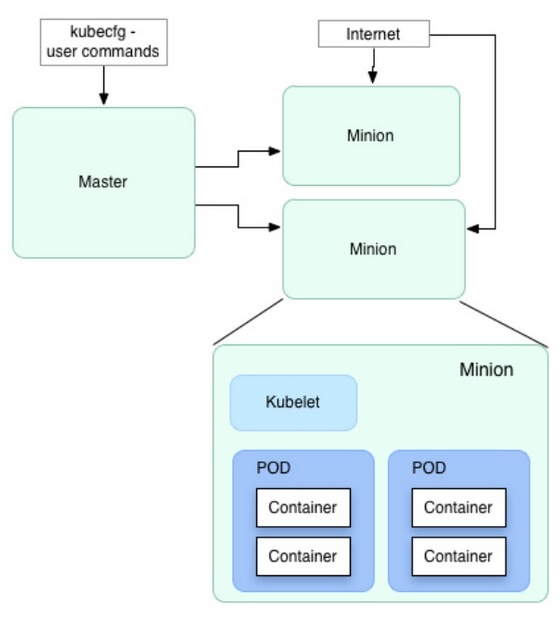
Kubernetes – Google分布式容器技术初体验
这篇讲的是作者对Google开源容器集群管理系统Kubernetes的初步体验。文章从分布式服务框架的配置管理、调度等核心需求出发,审视了Kubernetes如何解决这些痛点。 作者重点分享了几个关键概念的实际感受。比如,作为基本部署单元的Pod,以及通过Replication Controller实现自动化的实例管理与故障恢复——定义好副本数后,系统能自动维持服务实例的总量稳定。针对分布式系统的服务发现难题,Kubernetes的Service通过一个固定的虚拟IP来代理一组Pod,并解耦了具体的配置服务。 不过,体验过程并非一帆风顺。作者指出,目前Kubernetes版本迭代快、文档滞后,推荐新手直接使用GCE(谷歌计算引擎)环境以减少障碍。同时,他也客观指出了现有实现的一些局限,比如Service发现依赖环境变量、大规模服务下的iptables性能挑战,以及生产环境所需的高可用性仍有待验证。 总体来看,文章清晰地勾勒出了Kubernetes令人兴奋的设计理念与自动化能力,同时也坦诚地探讨了其当前阶段面临的环境易变性与成熟度挑战,为有意尝试的开发者提供了一份非常务实的体验报告。
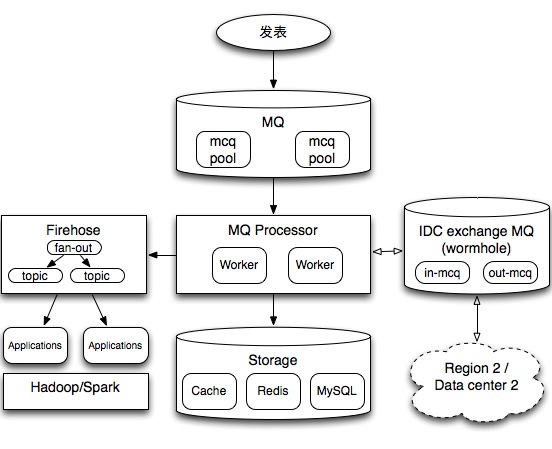
Feed消息队列架构分析
这篇讲的是微博为应对实时Feed流挑战而构建的消息队列架构。作者从数据流处理从离线走向实时的行业趋势切入,详细拆解了支撑海量社交信息流的底层架构。 核心是一个由三部分构成的体系:中间是feed主流程处理,通过MQ worker异步写入缓存和数据库,完成核心的削峰填谷;左侧是流式计算,用于大数据实时分析;此外还有负责多机房数据同步的“虫洞”模块。整个系统建立在几个关键单元上:单机队列MQ、支持一对多投递的统一通道Firehose(具备基于社交关系的fan-out能力),以及无状态的Worker。 架构设计上,文章强调了其高实时性(要求100ms内处理完成)、线性可扩展性与超高可用性(99.999%)。最后,文章还对比了LinkedIn Databus、Apache Storm和Kafka等技术路线,解释了为何其业务主动写入事件的方案在复杂分库场景下,比数据库触发方案更具原子性和简洁性。
Feed架构-我们做错了什么
这篇讲的是微博技术团队在Feed架构演进中的一次坦诚复盘与反思。作者从团队过去几年成功解决的工程挑战切入——包括通过冷热分区设计应对长尾数据访问、利用数据库拆分实现存储扩展、依托缓存分级支撑百万级QPS,以及建设高可用的SLA体系。 但文章的重点不在这些成就,而是深入剖析了基于用户关系的分发架构在用户侧引发的“信息过载”问题。核心观点是:架构在解决了可扩展性与性能问题后,却造成了内容组织与消费效率上的新瓶颈。具体表现为:当前架构天然基于用户关系维度组织数据,这很难服务于更高效的“兴趣阅读”需求;同时,低质内容识别、实时反垃圾算法仍面临巨大技术挑战;此外,社交关系带来的“可解释性”要求(用户期望看到好友内容)也与纯粹的算法排序存在矛盾。 作者通过这次复盘,揭示了一个关键认知:Feed架构的难题已从纯粹的后端扩展性问题,转向了如何通过技术更好地理解与满足用户兴趣,同时平衡产品体验的复杂层面。这对于思考推荐系统与社交产品架构的未来方向,提供了很有价值的视角。
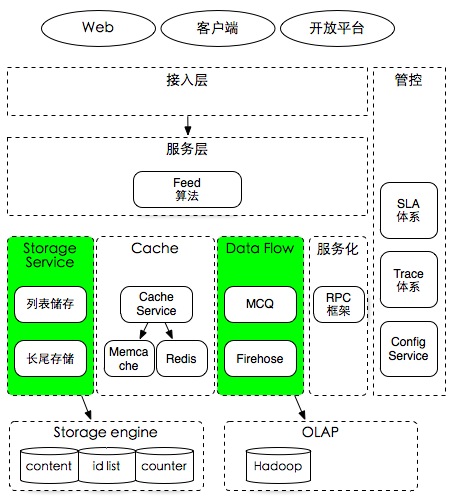
标准化与可复用杂谈
这篇讲的是从一次具体的线上问题排查说起,引申出对软件工程中“标准化”与“可复用”的思考。作者描述了一个典型场景:用户反馈的问题经过层层传递,工程师最后发现是某台服务器在特殊情况下启动了错误版本,导致返回数据异常。这背后暴露的是从代码测试、服务调用到上线发布的全流程中,处处依赖人工细心所潜藏的高风险。 文章的核心观点在于,将全流程中那些不易变的单元(如测试、服务交互规范、发布步骤)进行标准化,并用程序来控制,可以从源头减少低级错误。作者以一个深度使用消息队列但因标准化和抽象不足,导致经验难以复用的团队为例,说明了这一点。同时,文章也对比了国内外对工程师严格要求的差异,指出在业务驱动、快速交付的压力下,形成高质量代码共识与推动标准化建设的不易。 文章的启发在于,它并非空谈架构,而是从运维和开发的共同痛点出发,论证了标准化对于解放工程师精力、提升系统可靠性的实际价值,尤其适合那些正被重复性故障和低效协作困扰的技术团队反思。
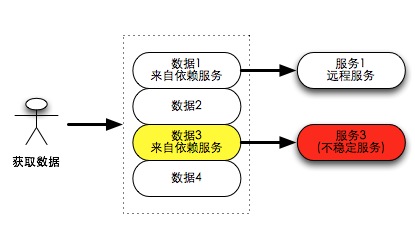
面试题 – 为什么我的朋友圈不见了?
这篇文章从一个常见但棘手的分布式系统问题切入:当一个数据聚合服务需要从多个远程服务获取数据,而其中一个服务不可用时,架构师应该如何选择容错策略? 作者详细剖析了三种典型方案。方案一是直接忽略失败的部分数据(优雅降级),虽然损失最小,但可能导致用户体验不确定。方案二是遇到任何失败就返回整体错误(503),完全依赖调用方的缓存与容错能力,否则用户会看到白屏。方案三则是自定义返回格式,显式告知哪些数据加载成功、哪些失败,但这大大增加了前后端的复杂度。 文章并未止步于此,而是进一步引入了“未读数”这一常见功能,将问题场景变得更复杂:即使主数据列表因服务不稳定而缺损,如果能单独提供一个准确的未读数,用户体验和系统效率会如何变化?这使得对三种方案的权衡更加微妙。 整篇文章的核心价值,不在于给出唯一答案,而是系统性地呈现了架构师在“数据完整性”、“用户体验”、“系统复杂度”和“服务可靠性”之间必须进行的现实权衡。它启发我们思考,在微服务架构下,如何设计既健壮又不过度复杂的容错机制。
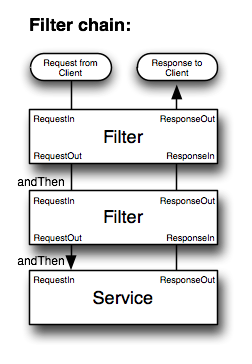
应用层的容错与分层设计
这篇讲的是分布式系统中,如何为应用层远程调用构建健壮容错体系的实践思考。文章从实际项目问题出发,指出系统内部服务间远程调用的不可靠性——无论是网络波动、硬件故障还是服务本身变慢,都可能像多米诺骨牌一样拖垮整个系统。单纯依赖服务端容错还不够,调用端(应用层)必须有独立的防御设计。 作者以微博团队的实践为例,分享了不同场景下的容错策略:访问MySQL时,写操作直接抛异常,读操作则有多级Failover;连接Redis或Memcached则需设置超时、异常标记、定期探测,并通过一致性哈希切换到备份节点;调用HTTP接口则要短超时、谨慎重试,并配合业务降级。 这些分散的实现暴露了问题:各客户端独立编码,原理相通却无法复用,维护成本高,且同步调用消耗大量线程资源。文章进而探讨了统一解决方案的可能性,参考了Twitter的Finagle框架思路——将容错、重试等策略抽象为“Filter”,与服务和Future模型结合,实现异步化的通用网络客户端。一个理想的统一client应该具备分层设计(服务层、网络层)、可扩展协议支持,并内置负载均衡、Failover等高可用能力,最终让开发者更专注于业务逻辑而非繁琐的容错细节。
为什么长尾数据的翻页技术实现复杂
这篇讲的是长尾数据翻页的技术复杂性。作者从Key-list类型数据(如好友列表、评论ID列表)的翻页需求出发,指出大部分数据长度较短时,简单的LIMIT offset方案尚可应对,但当数据量达到百万级且访问深页码时,该方案性能会急剧下降。 文章核心对比了两种翻页实现:“扶梯方式”(只提供上一页/下一页)与“电梯方式”(支持精确跳转至任意页)。作者解释,扶梯方式通过记录最后一条ID实现O(log n)复杂度的高效查询;而电梯方式因依赖LIMIT offset,在MySQL中需扫描前所有行导致O(n)的复杂度,且难以缓存。 面对更大数据规模,文章进一步讨论了分布式数据分片策略。按用户uid分片可高效读取,但数据冷热不均导致存储成本高昂;引入时间维度分片虽缓解存储压力,却带来了数据滚动自动化难、需额外二级索引等新问题。作者最后指出,现有方案均非理想,为后续探讨更优的长尾翻页设计埋下了伏笔。

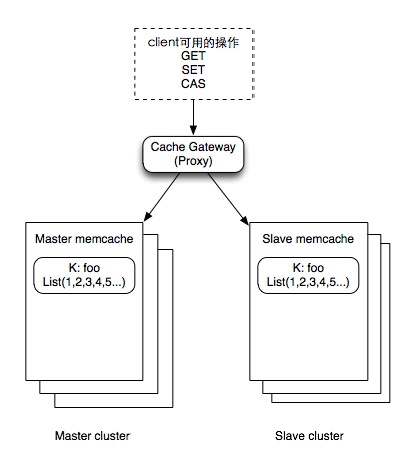
分布式缓存的一起问题
这篇文章聚焦于分布式缓存主从架构中一个典型的“踩坑”场景:当master节点突发故障时,原本设计用于保障数据一致性的CAS(Compare-and-Swap)流程却会导致slave副本数据静默过期。作者从实际业务故障出发,剖析了问题根源——master cas失败后并未对slave执行set操作,导致新变更无法写入缓存。 文章进一步探讨了自动切换master角色为何不可行,以及手工切换或采用“delete slave”或“设置短过期”等补救方案时,仍需面对命中率下降、接口职责模糊等棘手权衡。最终,作者将问题抛回给读者:在这种对可用性与一致性都有要求的场景下,一个更完美的解决方案应该如何设计?
享受造轮子的乐趣
这篇讲的是“重复造轮子”在技术圈内常被讳莫如深,但作者认为,有时大胆造轮子不仅无妨,反而是技术创新和团队成长的重要路径。 文章以Linux和搜索引擎领域的创新为例,指出若当年坚持“不造轮子”,可能就没有今天的开源系统和竞争格局。作者区分了“设计”与“使用”技术的不同层次,强调为用户提供更好方案的目标,常常需要我们跳出直接使用现有产品的思路。 更重要的是,造轮子本身的价值:它能帮助团队深入理解领域,启发重新思考与改进。同时,富有挑战的项目还能吸引顶尖人才——优秀开发者渴望解决难题,而这类“轮子”正好提供了舞台,从而通过技术杠杆推动业务。但作者也提醒,同一公司内无意义的重复不可取,关键在于把握“农闲”与“农忙”的时机,让积累在需要时发挥作用。
结网随想
读完图灵的《结网》,这篇技术视角的随想从产品经理与技术的关系、团队管理等维度分享了几个深刻观察。 作者首先点明,懂技术虽非产品经理的必要条件,但对技术缺乏理解往往会限制产品视野,拥有更深技术理解的产品经理更具竞争优势。书中关于创新者与模仿者的案例也引发思考:从AltaVista到Google、Napster到iTunes,模仿者屡屡成功,根源常在于创新团队缺乏兼具技术远见与管理能力的核心人才。 在团队协作上,作者借用漫画理论指出,领导者在传达愿景时,给予一个抽象而宏大的目标,比事无巨细的指示更能激发团队潜力,这为有想法的成员提供了翱翔空间。此外,文章强调了危机管理中“坦诚透明”的文化至关重要——敢于直面问题并公开进展,是团队与领导者值得信赖的标志。 这些观点不仅源于书本,更结合了作者对技术人才生态的思考。对于产品与技术从业者而言,这些从实战经验中提炼的见解,或许能提供超越操作层面的启发。

微观架构及宏观架构
这篇文章从工程师的成长路径出发,探讨了软件架构设计中两个相辅相成但思维模式迥异的层面。作者指出,许多工程师从解决排序算法效率、提升代码可读性这类“微观架构”问题起步,这些成果直观且易于度量。然而,随着系统规模扩大,“宏观架构”——即关乎全局效率与成本的顶层策略设计——的价值便凸显出来。 文中用一个形象的对比阐释了这种思维转换:追求缓存命中率最大化是微观视角,而从全局出发,接受长尾数据的访问延迟,可能使整体成本下降一个数量级且性能影响甚微。作者进一步分析,从专注细节的微观思维转向宏观架构时,成果往往不如提升单个模块QPS那样立竿见影,更像是一种“虚”但至关重要的战略能力。 文章的核心观点在于,微观与宏观如同战术与战略,缺一不可。优秀的工程师团队需要合理的微观与宏观人员配比,架构师也需具备对代码细节的理解,才能做出正确的技术判断。文末列举的如C10k问题、SPDY协议、事件模型等断言,也邀请读者一起实践这种从微观细节到宏观影响的思考视角。
“connect the dots” 随想
这篇随想以乔布斯经典的“connect the dots”理念为切入点,探讨了成功叙事之外,个人成长与积累的本质。作者指出,许多年轻人在选择面前感到迷茫,往往源于对“有形”功利目标的过度追求,而忽视了日常积累中那些无形的“点”。文章进而从做人、交友与专业选择三个维度展开论述。 做人需以诚信与自省为根基,成为值得信赖的人;交友则要追求真诚互助与价值输出,如同纽曼所描述的理想学习共同体。这两者是“connect the dots”的基础,但目的并非直接兑换利益。在专业方向上,作者结合历史案例,强调突破视界局限、寻找良师与平台、以及持之以恒的重要性。 整篇文章的核心观点在于,人生关键的“连接”往往发生在回望之时。那些看似无目的的日常修养、真诚交往与专业沉淀,才是未来得以串联成图的关键节点。

演讲小组的第一次活动
这篇讲的是作者和同事基于胡适“谈话说理”的启发组织演讲小组后的真实观察。他们发现,即便有多次演讲经验,大多数人依然缺乏对“演讲本身”的反馈——比如逻辑、表达和材料运用。 第一期活动后总结出几个关键痛点:纯理论观点容易让听众昏昏欲睡;缺乏实践案例或故事支撑的观点难以引发共鸣;对素材不熟悉会导致脱稿后辞不达意,说明“所思所想”尚未真正内化;此外,PPT与内容无关、推论无法支撑结论等逻辑问题也屡见不鲜。 文章并非泛泛而谈演讲技巧,而是从一次具体实践出发,拆解了技术人表达能力中的常见盲区。对于同样需要清晰传递复杂想法的工程师来说,这些观察或许比通用演讲指南更有针对性。

跨领域人才
这篇讲的是2012年《三联生活周刊》对斯坦福大学的一次深度观察,它将这所名校称为“硅谷的心脏”。文章并非泛泛而谈学术成就,而是聚焦于一个关键视角:跨领域人才的培养。斯坦福的魔力,不仅在于它培养出众多技术创始人,更在于它如何刻意打破学科壁垒,让工程、商业、人文甚至艺术的学生在校园里就相互碰撞、协作。这种氛围催生的不是单一维度的专家,而是能理解技术、市场并洞悉人性的“桥梁型”人才,这正是硅谷持续创新的底层燃料。文章提醒我们,真正的创新生态,始于教育系统中那种敢于跨界、乐于融合的文化基因。
