最新文章
采集自各技术站点的近期文章。
Oracle JDBC中的语句缓存
这篇讲的是如何在Java应用中,利用Oracle JDBC驱动提供的语句缓存机制,来优化数据库访问性能,核心目标是实现“一次解析,多次执行”的高效模式。 文章首先清晰梳理了Oracle数据库中硬解析、软解析等不同SQL解析方式的特点与潜在性能瓶颈,指出过多解析会导致latch争用等问题。随后,作者通过一个对比实验,直观展示了开启JDBC语句缓存前后的巨大差异:未缓存时,一条SQL语句执行200次就产生了200次解析;而开启缓存后,同样执行200次,解析次数仅为1次,显著降低了数据库负载。 实现的关键在于通过OracleConnection对象设置`setStatementCacheSize`和`setImplicitCachingEnabled`,这能为每个连接自动缓存使用过的PreparedStatement。文章还深入一层,介绍了如何通过`setExplicitCachingEnabled`及手工指定Key的方式,进行更精细的缓存控制,以避免缓存不常用语句造成的内存浪费。 通过具体的代码示例与数据库监控结果验证,文章为Java开发者提供了一个实用且效果明确的Oracle性能优化方案。
好的产品经理,差的产品经理
这篇讲的是 Ben Horowitz 在 1996 年,以 Netscape 产品管理部门经理的身份,对“好产品经理”与“差产品经理”做出的经典、直白对比。文章没有空谈职责,而是通过一系列具体的行为差异,勾勒出两种截然不同的职业画像。 好的产品经理被定义为“产品的 CEO”,他们基于对市场、竞争和产品的深刻理解来制定并毫无借口地执行计划。他们清晰定义“做什么”,有效管理团队,并用书面方式清晰沟通;他们聚焦于收益和客户价值,制定可执行的好产品。 而差的产品经理则充满了各种借口,从资源不足到技术同事能力问题。他们常常混淆“管理”与“执行”的边界,在“怎么做”的细节上自我感觉良好,却让团队聚焦于错误的指标(如功能数量),或者定义出无法落地的产品。 文章通过对比,核心揭示了优秀产品经理的关键特质:主人翁精神、强大的执行力、清晰的沟通以及以商业成果为导向的思维。即使成文多年,其中关于责任担当、有效协作和避免常见陷阱的洞察,对今天的从业者依然是一面清晰的镜子。
关于socket这个术语的来源
这篇讲的是“socket”这个在编程中无处不在的术语,究竟是从哪里冒出来的。作者从大家熟悉的中文译名“套接字”和“插口”入手,追溯了这个术语的权威出处。 文章引用了两本经典著作的不同视角:《Java TCP/IP Socket 编程》从应用编程接口的角度,强调socket是让程序通过网络互通的关键抽象;而《TCP/IP详解》则直接指出了它的技术本质——一个IP地址加一个端口号,并明确其来源是RFC793这份最早的TCP规范文档。 最硬核的部分是文章贴出了RFC793中对socket的原始定义。这里清楚地说明,socket是为了解决“单台主机上多个进程如何同时使用TCP”这个问题而设计的。一个socket(由网络地址和主机端口组合而成)可以被多个连接复用,这个设计思想一直沿用至今。 所以,这篇文章不仅仅是解释一个名词,更是一次对网络编程基石概念的考古。它把我们日常使用的工具,与几十年前协议设计者最初的那个简洁而巧妙的构想连接了起来。
深入浅出Session攻击方式之一 – 固定会话ID
这篇技术文章聚焦于Web安全中一种具体且危险的攻击手法:固定会话ID(Session Fixation)。作者从PHP应用普遍面临的安全挑战入手,深入剖析了攻击者如何诱使用户使用其预设的Session ID来访问系统,从而实现会话劫持。 文章不仅阐述了攻击原理——即攻击者通过URL参数(如`?PHPSESSID=1234`)等手段固定一个会话标识,并用直观的代码示例和测试过程演示了其危害性:只需访问特定链接,新浏览器就能“继承”之前浏览器的会话状态。更关键的是,文章给出了明确的防御方案:核心在于在用户登录、权限变更等关键节点,及时调用`session_regenerate_id()`函数重新生成Session ID,彻底切断攻击者的预设路径。 作者还进一步探讨了经验更丰富的攻击者可能先自行获取合法Session ID再实施固定攻击的场景,强调了防御措施需具备时效性和全面性。整篇文章由原理到实践,再到防御升级,为开发者提供了一份清晰的攻防路线图。

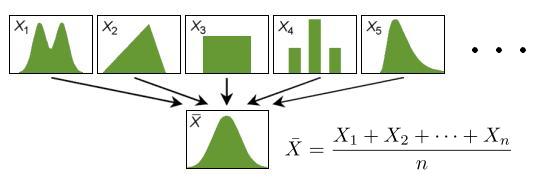
正态分布的前世今生(五)
这篇讲的是正态分布在19世纪如何从崭露头角到成为统计学基石的关键发展历程。作者从拉普拉斯和高斯两位巨人的工作切入,清晰地勾勒出正态分布在两大支柱学科中的奠基过程。 文章首先追溯到1776年,拉普拉斯为解决天文学中的彗星轨道问题,开始研究多个独立随机变量之和的概率计算。这一实践问题最终推动了中心极限定理的诞生,为正态分布在概率论中的核心地位打下了理论基础,使其成为描述“随机之和”的通用模型。 与此同时,在数理统计领域,高斯基于对天文观测误差的细致分析,大力提倡并推广正态分布,使其在误差理论与数据分析中畅行天下。文章特别提到高斯在处理测量误差时,如何将正态分布(即高斯分布)作为分析工具。 通过回顾这段历史,文章揭示了正态分布之所以能成为近代统计学“开疆扩土”的主角,正是因为它同时被概率论的理论框架(中心极限定理)和数理统计的实践需求(误差分析)所双重赋能,从而奠定了其在科学与工程领域无处不在的坚实地位。
数据的存储介质-磁盘的硬件特性
这篇技术文章深入剖析了机械硬盘的硬件特性,从基础构造讲到性能原理,非常适合需要理解存储底层机制的开发者。 作者从磁带机讲起,解释了磁盘如何通过电机旋转盘片、磁头移动寻道来实现随机访问,这个演进过程讲得清晰易懂。文章重点剖析了几个关键点:硬盘如何以“块”(通常为512字节)为单位进行读写,以及在异常断电时,系统如何通过在启动时清理未完成的数据块来保证数据的原子性,这是单机存储保证一致性的经典思路。 更硬核的部分在于对性能指标的辨析。文章厘清了 IOPS(每秒读写次数)、吞吐量(MB/s)和延迟之间的关系,并指出它们适用的不同场景:数据库更看重影响 IOPS 的寻道时间,而大文件存储则更追求吞吐量。作者还用“飞机运旅客”的比喻,巧妙地说明了适度增加延迟可以提升整体吞吐量的原理。 最后,文章总结了机械硬盘技术成熟、顺序读写性能好的优势,以及因机械结构导致随机访问性能下降的固有劣势。
数据的存储介质-磁盘的RAID
RAID作为存储领域的基石技术,其“分而治之”与“冗余复制”的核心思想,至今仍深刻影响着分布式存储系统的设计。这篇文章从数据存储的两个基本要素——通信管道与介质出发,清晰地拆解了RAID技术诞生的根本动因:通过合理组织多块磁盘,来突破单盘在IOPS与数据安全性上的瓶颈。 文章对几种经典RAID模式(RAID 0/1/5/1+0)的阐述并非简单罗列,而是抓住了它们的核心逻辑与权衡。例如,指出了RAID 0的并行读写优势、RAID 1的镜像成本,以及RAID 5通过XOR校验在冗余与空间效率间的折衷。特别值得玩味的是,作者点明了RAID 0+1与RAID 1+0在故障场景下的关键差异,解释了为何后者是更优的选择,并自然引申到GFS、HDFS等现代文件系统其实都采用了“先复制、再切分”的类似策略。 更深入一层,文章探讨了在单机环境下实现RAID时所面临的、类似于CAP问题的原子性写入挑战。它揭示了RAID卡如何利用“内存缓存+电池/SSD备份”这一巧妙而务实的方案来打破数据一致性的逻辑循环,既保证了性能,也解决了可靠性难题。文中对盘柜及新网络协议(如FC、iSCSI)的提及,则拓宽了读者对RAID物理实现形式的认知。 整体而言,这篇文章将RAID技术置于更广阔的存储演进史中,不仅讲清了“是什么”和“为什么”,更通过与分布式系统的类比,帮助读者理解了这一传统技术历久弥新的底层逻辑。
数据的存储介质-固态存储SSD
这篇讲的是SSD固态硬盘的性能内幕。作者抛开基础科普,直击几个核心痛点:为什么不同品牌的SSD读写速度差距巨大?为什么解决了磁盘寻道问题后,4K随机写仍是性能瓶颈?而所有问题的答案,最终都指向了一个关键角色——FLASH控制器。 文章从NAND闪存的底层特性说起,解释了SLC/MLC的区别、以及闪存“必须整块擦除”的特殊操作。正是这些硬件限制,导致了“写入放大”现象。作者指出,各家控制器处理垃圾回收、磨损均衡和写入策略的算法差异,直接造就了性能上的天壤之别。对于随机写瓶颈,文章分析了块回收跟不上写入请求时,延迟会从250微秒陡增至2250微秒的残酷现实。 最后,文章探讨了控制器放在专用芯片还是共享主机CPU上的不同路线之争,并展望了随着控制器算法优化和闪存成本下降,SSD将在高性能存储领域全面取代机械硬盘的趋势。读完能让人明白,SSD的水,远比“无机械结构所以快”要深得多。
网络传输协议AMF初探
这篇讲的是 AMF(Action Message Format)协议,一种专为高效数据传输设计的二进制格式。与传统的 SOAP/XML 文本传输方式不同,AMF 采用二进制编码,能高度压缩数据,特别适合传递大量资料——数据量越大,传输效率优势越明显。文章梳理了 AMF 的核心特点:它可以直接传输 Flash 内置对象(如 Object、Array、Date),服务器端能自动解析,大幅简化开发流程。 作者从 Flash Remoting 的实际选择出发,对比了 AMF 与 SOAP 的关键差异。AMF 不仅比冗长的 XML 更高效,而且因为它专注于支持 ActionScript 数据类型,在浏览器中体积仅需约 4KB(压缩后),而 SOAP 则庞大得多,且存在头部请求不支持的问题。文章还列举了 AMF 协议支持的数据类型及其对应的十六进制值,展示了其结构的紧凑性。 在实现层面,文章介绍了 AMF 基于 HTTP 的典型处理流程:从客户端请求、反序列化、服务处理到响应序列化,并提及 PHP、.NET、Python、Ruby 等主流语言都已拥有成熟的 AMF 框架(如 AMFPHP、FluorineFx),开发者可以快速实现 Flash 与后端数据库的通信。 总的来说,这篇文章清晰地说明了 AMF 如何通过二进制优化和对 Flash 生态的专注,在特定场景下(尤其是需要高效、轻量交互的 Web 应用中)成为比 SOAP 更具优势的选择。
细说促销(三):促销的实施
这篇讲的是促销活动执行环节的常见问题与解决方法。作者从“策划”这个词说起,将“策”(创意方案)与“划”(项目管理、沟通执行)区分开来,点明许多活动“想得很好,做得很差”的核心矛盾。 文章指出,执行的第一步是预算规划。钱不能只花在买广告上,更应投入在创造有吸引力的活动内容本身。文中以“百分一女装”的全球外拍为例,说明他们花费数十万用于拍摄和广告,最终引入的流量是普通广告的5倍以上,关键就在于用独特内容驱动了口碑传播,而非单纯购买流量。 在具体实施上,作者强调了几个关键点:一是做好清晰的项目分工与时间管理;二是策划人必须主导“客户体验”,而非完全交给设计师。策划需明确传达页面的核心信息(“只要…就能…还能…”),确保用户第一眼就抓住重点。文中通过一个页面设计混乱的实例,说明信息堆砌会损害用户认知。最后,执行要“灵活而严肃”:广告和页面可以持续优化调整,但活动规则必须保持稳定,任何修改都需慎之又慎。
细说促销(二):促销的玩法
这篇讲的是如何设计简单有效的促销策略。作者从一个极易被忽略的误区切入:一个卖家做“满148元送手套”活动,销量涨了40%,但因店铺平均客单价本就是156元,这实为“白送”。由此引出核心——促销的关键在于那个“满”字,是让客户“跳一跳够得着”的门槛。 文章提炼出一个万能公式:“只要(商家条件)……就能(消费者利益)……还能(附加价值)……”。以此框架,作者对比了三种主流玩法:“满就送”的赠品要选听起来不错、实际成本低的大牌货;“满就减”看似最直接,但容易陷入纠结表面折扣率,真正的学问在于设计如何让客户为“凑单”多花钱;“满就返”虽常被诟病,但用好了对促成临门一脚和提升复购频次效果最强。 作者特别指出,所有促销策略的底线是必须能在20秒内用最简单的话向普通人说清楚,否则就容易失败。整篇通过实战案例拆解了“促销促进销售”的过程本质:就是用条件,换取消费者更多的购买行为。
细说促销(一):促销的本质
这篇文章属于“事件复盘与观点”类,作者通过剖析具体案例,深入探讨了电商促销的本质与常见误区。 核心观点是,促销绝非“照猫画虎”那么简单,它是一门“招式简单、内功复杂”的学问。文章以运动品牌经销商“古星”的实战为例:从“两件更便宜”成功清夏装库存,到“满99加5元送袜子”巧妙提升客单价,再到“满139加29元送宜家毯子”因价格门槛和物流问题遭遇滑铁卢。这些起伏揭示了促销成败的关键——时机、商品特性、价格心理和执行细节。 作者犀利地指出了几个常见陷阱:将促销变常态(如常年2折的“华伦天奴”,会彻底摧毁品牌价值)、盲目模仿(卖沙发学卖首饰搞“两件更便宜”)、以及手段单调(只会打折)。促销的本质是通过提供额外价值,在产品生命周期的特定阶段(如上市推广、销量瓶颈期)来短期、有效地提升销售额,其公式无外乎提升客单价或销售量。 文章最后强调,每一次促销都需要一个合理的“借口”,这如同古代的檄文,能给消费者一个消费的理由和名正言顺的心理暗示。理解“凭什么做”和“什么时候做”,远比学会“满减、秒杀”这些招式本身更重要。对于电商运营者而言,这篇文章提醒大家,促销前多问一句“为什么”,或许比直接套用模板更有效。
苹果信息推送服务(Apple Push Notification Service)使用总结
这篇讲的是如何在 iOS 应用中接入并实现苹果官方推送服务(APNS)。作者从 APNS 的核心概念出发,明确了它免费、但不可靠且有大小限制的特点,并梳理了其依赖硬件 token 的工作流程。 文章的重点在于配置和实现。它详细拆解了从申请开发者证书、配置 App ID 与 Provisioning Profile,到使用 OpenSSL 命令合并生成最终推送证书的每一步,特别指出了证书环节容易踩坑。随后,通过具体的 Objective-C 代码示例,演示了如何在客户端注册通知、获取设备 token,以及处理应用在不同状态下收到的推送消息。最后还附上了用 PHP 编写的简易推送测试脚本,形成了一个从配置到验证的完整闭环。 如果你正为 iOS 项目接入推送功能发愁,尤其是对复杂的证书配置步骤感到头疼,这篇实操指南能提供清晰的路线图和避坑参考。
更极致的搜索推荐——“去哪儿酒店”搜索体验【2013年9月版】
作者从2013年去哪儿网的酒店搜索功能出发,深入剖析了平台如何针对两类用户——目标明确型与无明确目标型——设计差异化的服务路径。对于前者,去哪儿提供了“距离筛选”等高效工具,搜索体验流畅;但针对后者,尽管设有价格、档次等个性化搜索入口,用户在结果页仍常陷入筛选的困惑。 文章的核心观察在于,去哪儿虽在入口做了区分,但在搜索结果呈现上,对无目标用户的支持仍显不足。作者进而提出,应引入智能推荐机制,例如基于“去中关村的用户大多住此类酒店”的群体偏好数据进行引导,甚至将推荐延伸至搜索起点,增加“游玩”、“散心”等情景化入口。这篇分析不仅点明了当时产品设计的亮点与缺口,其关于“用推荐服务缓解用户决策焦虑”的思考,在今天看来仍具启发意义。
人人都用 Retina 屏幕的 MacBook Pro 笔记本电脑
这篇讲的是作者从个人使用 Retina 屏 MacBook Pro 的体验出发,强烈推荐这款笔记本成为每个人的首选。他认为,Retina 屏幕的高分辨率是核心优势——其像素数量是普通屏幕的 4 倍,通过将 12px 字体放大到 24px 并后退观看的比喻,直观展示了字体渲染的细腻效果。同时,作者强调 Mac OS X 的字体渲染技术天生适合高分辨率,低分辨率下视觉效果甚至不如 Windows 95,因此坚决反对购买非 Retina 屏幕的机型。 除了屏幕,作者将 SSD 硬盘视为性能关键,指出电脑速度的瓶颈早已是硬盘而非 CPU,批评 PC 笔记本常搭载慢速机械硬盘是“过时的骗人货”。在体验上,MacBook Pro 的即点即用、无风扇噪音和轻量设计,与 PC 笔记本的唤醒延迟和松散感形成鲜明对比。设计细节上,他推崇 MacBook Pro 的对称美学和完整质感,认为这超越了 PC 的拼凑感。 软件层面,作者欣赏 Mac OS X 的朴素界面,并指出 MacBook Pro 可用于 iOS 和 Android 开发,提供免费的 Xcode 环境。最后,他以成本效益论证:一台万元 MacBook Pro 相比占地费噪的台式机更具性价比,并预测苹果笔记本将持续领先多年。文章的核心启发是,选择笔记本时应优先考虑屏幕、SSD 和整体设计,而非盲目追求硬件参数。
360的产品经
这篇文章从360这家争议不断但产品屡屡成功的公司切入,分享了三个值得琢磨的产品思维。 第一,用户骂你,往往是对的。作者指出,用户即使对最简单的设置抱怨,也揭示了真实需求,而不是他们“智商有问题”。产品人的傲慢往往会掩盖真正的用户痛点。 第二,创新不止于发明,改进体验也是质变。文章以360和苹果为例,说明他们可能没有开创品类,但通过优化实用性赢得了用户。这种“实用性创新”是很多成功产品的共同特质。 第三,理解弱需求背后的强动机。很多时候用户明知不对仍会这么做,关键不是说教,而是设计更有效的方式来引导行为。这比单纯指出问题更考验产品设计。 虽然360这家公司本身争议不断,但文章提炼出的这些方法论——倾听抱怨、聚焦体验改进、洞察行为动机——确实点中了产品设计的一些要害。对于产品经理和开发者来说,这些来自实战的观察,比纯粹的理论更有嚼头。
如何提高Oracle进程的优先级 - 实现进程实时调度
这篇讲的是在繁忙的Oracle系统中,如何为关键后台进程争取更多的CPU资源。作者从Oracle 10gR2引入的一个隐含参数 **_high_priority_processes** 出发,介绍了实现进程实时调度的具体方法。 文章核心是讲解这个参数的使用:通过在数据库中设置它(例如 `_high_priority_processes="LMS*|LGWR|PMON"`),可以提升指定进程的优先级。作者通过Linux下的实际测试展示了效果:设置前PMON进程为普通分时调度(TS),重启数据库后即转变为实时调度(RR),从而能优先获取CPU。文章还对比了不同操作系统下的差异,例如Solaris上会使用RT实时模式。 最后,作者也提醒了实际应用中的细节,比如在RAC环境中,提升所有LMS进程的优先级可能并非必要,反而会抢占资源,需要根据业务负载审慎配置。整篇文章从原理、设置方法到实际效果和注意事项,提供了一套完整的技术思路。
字体勾边渲染的简单方法
这篇讲的是游戏开发中字体勾边渲染的优化方案。作者从手游和端游的大量实际需求出发,希望能直接利用系统字体动态生成勾边,而避免耗时的离线预处理打包。文章先梳理了传统“多遍绘制”方法效率低,以及流行的SDF方法需要离线生成字模数据的局限,也提到了苹果平台API生成的带勾边字模信息存储困难——轮廓与字体主体信息混合,难以用单通道记录。 作者的核心创新在于,提出了一种巧妙的单通道编码方案来解决这个存储矛盾。他观察到,勾黑边后的白字,其alpha值小于1.0的像素必然都是纯黑色的。利用这一特性,他将alpha通道信息与灰度信息映射到同一个通道的不同数值区间:将alpha为1.0的像素的灰度值映射到0.5至1.0区间,而将alpha小于1.0部分的像素值映射到0至0.5区间。这样仅损失1bit精度,就在一张单通道贴图中完整保存了轮廓和填充信息。 最终还原时,通过一个极其简单的shader(Alpha := clamp(G * 2.0, 0, 1.0); Color := clamp((G-0.5) * 2.0, 0, 1.0))即可从灰度图G中解码出原始的颜色与透明度。这个方案规避了双通道贴图的硬件兼容性问题,在保证渲染效果均匀平滑的同时,显著降低了实现复杂度和资源占用,为动态字体勾边提供了一个轻量级的实用解法。
