熬夜
作者回顾了自己在北京近二十年来,几种不同性质的“熬夜”经历。从学生时期为赚取生活费、在机房“偷电”学习计算机的被动熬夜,到初入IT行业为掌握新技术而如饥似渴的主动学习,再到后来出入三里屯工体、社交饮酒带来的“模糊”熬夜,最终在创业阶段,熬夜成为伴随日常的“理所当然”。 文章并非讨论健康建议,而是通过个人时间线,呈现了一个技术人生活状态的变迁缩影:初期是生存与求知驱动,中期混杂着社交惯性,后期则是被事业责任与焦虑裹挟。作者坦言,熬夜早已成为难以摆脱的习惯,并坦诚表达了对未来的担忧。 这篇分享的动人之处在于其真实性,它映照出许多同龄人相似的矛盾——一边熬夜,一边焦虑。最终,作者送上了朴素的祝福,希望所有熬夜的朋友都能身体健康。
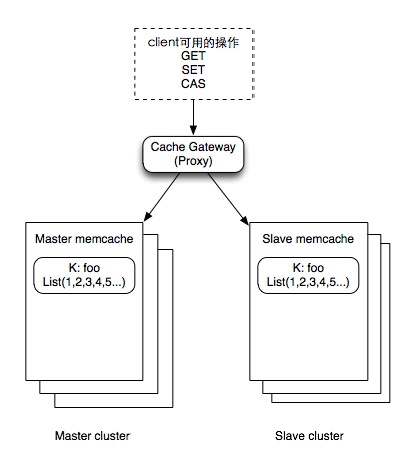
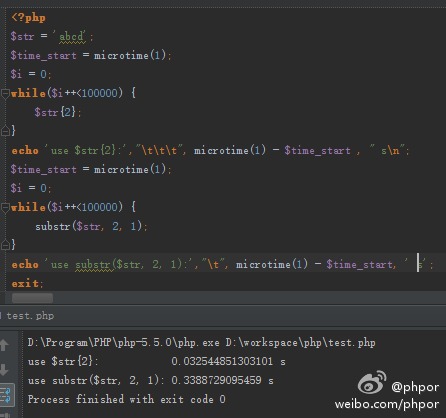
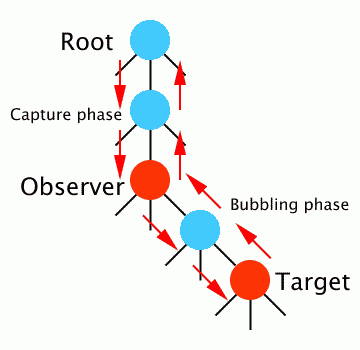
本机暂存