事无巨细 Hadoop2.6.4 环境搭建步骤详解
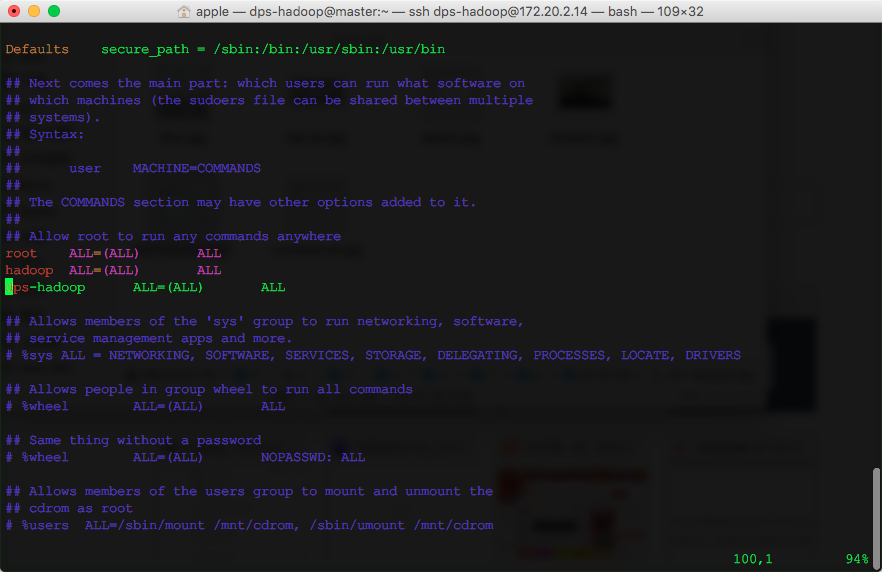
这篇讲的是作者基于自己的Mac开发机,在CentOS 6.5服务器上从零搭建Hadoop 2.6.4环境的完整历程。作者事无巨细地记录了每一步操作和背后的思考,像一位耐心的向导。 摘要从最基础的环境准备开始,详细说明了如何配置SSH免密码连接以提升后续操作效率,并推荐了ssh-copy-id这一可靠方法。接着,文章阐述了如何创建独立的dps-hadoop用户和用户组,以及为其配置sudo权限,体现了规范的权限管理思路。在基础设施层面,作者分享了如何配置本地DNS服务器,并给出了修改网络配置文件以永久生效的具体位置。 核心的Hadoop安装部分,文章涵盖了JDK 8u77的下载、安装与环境变量配置,并特别指出了将JAVA_HOME写入~/.bashrc而非全局配置文件的重要性。最后,详细说明了如何下载并解压Hadoop 2.6.4,以及配置HADOOP_HOME的关键步骤。整篇记录覆盖了从连接、用户、环境到软件安装的全链条,对新手而言,这份笔记省去了大量摸索和试错的时间。