本文详细记录了OneCoder通过自己的Mac环境,在开发服务器(CentOS 6.5)上搭建Hadoop的详细过程。因为事无巨细,所以可能会”跑题”。
ssh连接免密码配置
由于配置过程中需要频繁的进行ssh连接到开发服务器执行命令以及通过scp命令向服务器拷贝文件等依赖ssh连接的操作。所以,配置本地环境跟服务器之间的ssh免密码连接可以有效的提升工作效率。
由于我本机已经生成过公钥,所以我只需将已有的公钥拷贝到服务器即可。推荐使用ssh-copy-id命令,简单又不会出错。手动copy 再append的公钥文件尾,容易因为操作问题,造成无法正确识别公钥。
注:如果你没有生成过公钥,可通过ssh-keygen命令生成公钥。走默认配置即可。
在我的mac上,居然还没有安装ssh-copy-id命令。通过brew 命令安装即可。
brew install ssh-copy-id然后copy公钥到指定主机
ssh-copy-id root@172.20.2.14其中, root@172.20.2.14改为你需要访问的服务器的 用户名@IP。根据提示输入一次密码。成功后,所有基于ssh的命令你只需要通过用户名@IP 即可直接访问服务器。
新用户、用户组创建
为了更好的权限控制,养成良好的Linux使用习惯,我们首先创建一个管理和使用hadoop集群的用户(组)dps-hadoop。这也是hadoop集群管理所需要的环境配置。
groupadd dps-hadoopuseradd -d /home/dps-hadoop -g dps-hadoop dps-hadoop考虑到难免需要使用sudo提权的情况,给该用户配置到sudo名单下, 修改/etc/sudoers文件。
vim /etc/sudoers新增一行记录:
dps-hadoop ALL=(ALL) ALL 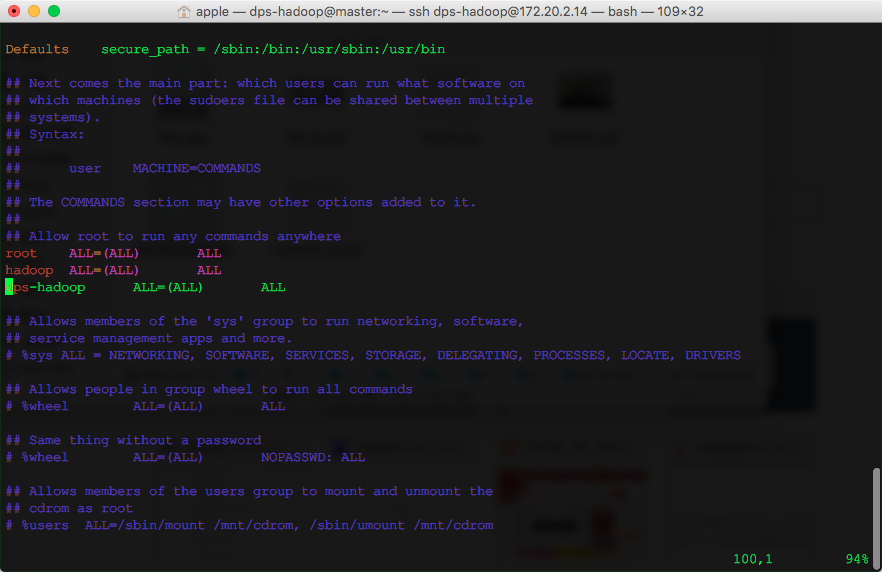
此后,我们均使用dps-hadoop用户进行操作。
配置本地DNS服务器
之前我介绍了如何用Docker搭建本地的DNS服务器,这里终于派上用处。如果你没有本地DNS服务器,那么你修改/etc/hosts文件也可以。对于CentOS,临时生效的配置文件在
/etc/resolv.conf你可以看到该文件开头提示你,该文件是自动生成的。重启网络服务会覆盖,永久配置修改
/etc/sysconfig/network-scripts/ifcfg-eth0修改其中的
DNS1=172.20.2.24其中ifcfg-eth0,改为你自己的网卡名即可。
安装JDK
Hadoop是Java开发的,自然需要依赖jre运行。我采用了比较本的方法,现在oracle官网下载jdk-8u77到本地,再通过scp命令拷贝到服务器的方式。进入jdk所在文件夹执行
scp jdk-8u77-linux-x64.rpm dps-hadoop@172.20.2.14:~/download其实通过wget也可以下载,但是网上给出的命令
wget --no-cookie --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F" http://download.oracle.com/otn-pub/java/jdk/7u10-b18/jdk-7u10-linux-i586.rpm我试了多次均未成功。我自己有个笨方法,就是先通过浏览器获取下载获取到真正的下载地址

然后再通过wget下载:
wget http://download.oracle.com/otn-pub/java/jdk/8u77-b03/jdk-8u77-linux-x64.rpm?AuthParam=1460511903_6b2f8345927b3fc4f961fbcaba6a01b3下载后,你可能需要进行一次重命名,将多余的?AuthParam后缀去掉。
mv jdk-8u77-linux-x64.rpm?AuthParam=1460511903_6b2f8345927b3fc4f961fbcaba6a01b3 jdk-8u77-linux-x64.rpm最后,安装jdk
rpm -i jdk-8u77-linux-x64.rpm配置JAVA_HOME
修改dps-hadoop用户自己的环境变量配置文件。
vim ~/.bashrc注意:网上提到了配置环境变量的方式有很多,粗暴的就是直接配置在/etc/environment或/etc/profile等全局配置文件中,对所有用户生效。不推荐这种做法。对于用户级的变量也有两个~/.bash_profile和~/.bashrc,区别请自行研究。如果你想通过执行start-dfs.sh等脚本,远程起停hadoop集群,那么请配置在~/.bashrc中,否则hadoop会找不到你配置的环境变量。
例如:Error: JAVA_HOME is not set and could not be found.
添加
export JAVA_HOME="/usr/java/jdk1.8.0_77"不建议配置到/etc/environment 下,因为会对所有用户生效。
安装Hadoop 2.6.4
根据官网介绍,Hadoop项目实际包含以下模块:
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
首先,直接通过wget,从镜像站下载。
wget http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz解压到用户目录
tar -xvzf hadoop-2.6.4.tar.gz -C ~/配置HADOOP_HOME,同样修改~/.bashrc文件。增加
export HADOOP_HOME="/home/dps-hadoop/hadoop-2.6.4"在其他节点重复上述所有配置操作。
添加用户
配置dps-hadoop用户,从master到各slave节点间的ssh免密码访问。
修改DNS服务器地址
安装JDK
下载解压Hadoop
配置Hadoop环境变量
配置集群
从模块角度理解,配置hadoop集群应包括HDFS、YARN和MapReduce这三部分配置。
HDFS配置
不考虑调优,仅从功能可运行上来理解,HDFS配置需要分别配置namenode、datanode的ip和端口号。数据备份份数。数据存放地址。因此配置如下:
namenode
core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>/home/dps-hadoop/tmpdata</value> </property></configuration>hdfs-site.xml<configuration><property> <name>fs.default.name</name> <value>hdfs://master:54000/</value></property><property><name>dfs.namenode.name.dir</name><value>/home/dps-hadoop//namedata</value> </property><property><name>dfs.replication</name><value>2</value> </property></configuration>Datanode
core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>/home/dps-hadoop/tmpdata</value> </property></configuration>hdfs-site.xml
<configuration><property> <name>fs.default.name</name> <value>hdfs://master:54000/</value></property><property><name>dfs.datanode.data.dir</name><value>/home/dps-hadoop/datadir</value> </property></configuration>这里只有core-site.xml里的hadoop.tmp.dir的配置是我们之前没有提到的。该配置是修改临时文件的存储路径,避免因为系统重启造成的临时文件的丢失,从而导致集群不可能用的情况出现。
启动HDFS集群
跟使用硬盘一样,HDFS使用前也需要格式化
bin/hdfs namenode -format然后启动
sbin/start-dfs.sh通过控制台,可查看HDFS集群状态
http://172.20.2.14:50070/一个插曲
启动时候发现一个WARN日志。
16/04/19 13:59:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
无法加载本地库。从stackoverflow上答案来看,主要有三种可能。
没有指定java.library.path环境变量。
本地库跟系统不兼容。(64位系统,提供的是32位的本地库)
GLIBC版本不兼容
通过file命令查看
file lib/native/* 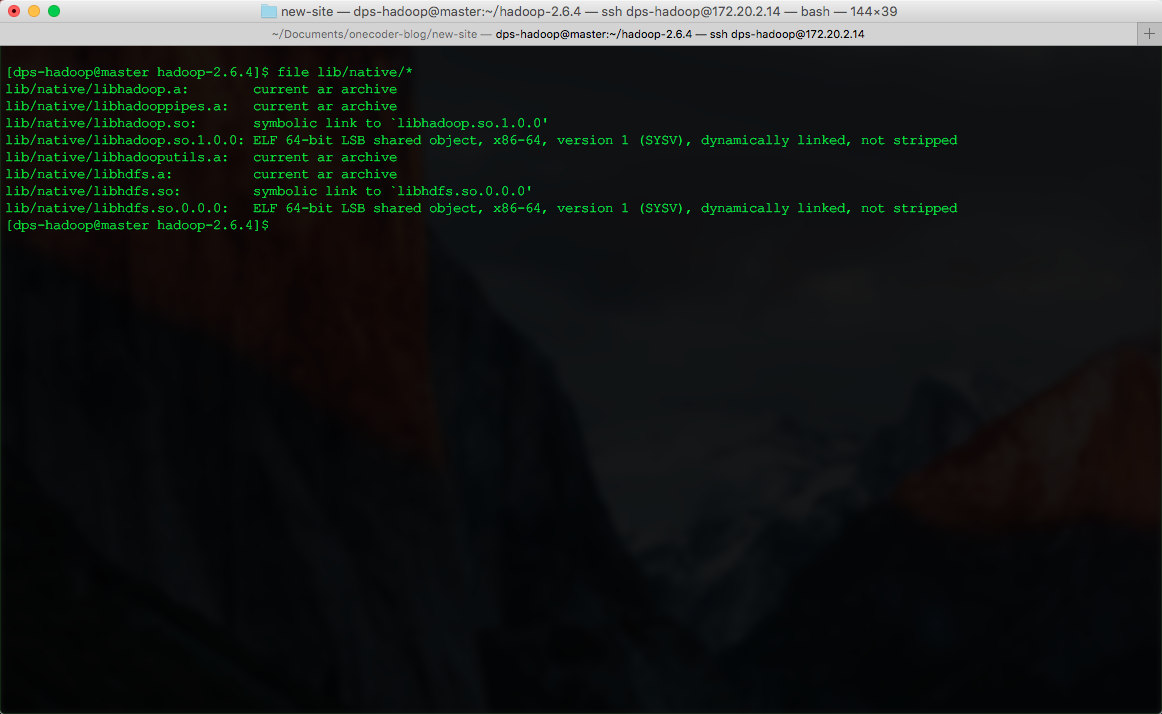
已经是64位的本地库。
修改log4j.properties 打开本地加载的debug级别
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=DEBUG再次启动发现问题
16/04/19 14:27:00 DEBUG util.NativeCodeLoader: Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: /home/dps-hadoop/hadoop-2.6.4/lib/native/libhadoop.so.1.0.0: /lib64/libc.so.6: version `GLIBC_2.14’ not found (required by /home/dps-hadoop/hadoop-2.6.4/lib/native/libhadoop.so.1.0.0)
通过
ldd --version发现我本地环境的版本是2.12的。这个不升级系统版本很难解决。把log 改成ERROR,暂时眼不见心不烦吧。
YARN配置
在YARN里,主节点称为ResourceManager,从节点称为NodeManager。根据理解,需要告知NodeManager, ResouceManager的通信地址。 对于ResourceManager来说,所以的从节点已经配置在slaves中了。因此,配置如下:
NodeManager
yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>master</value></property></configuration>启动yarn,主节点执行
.sbin/start-yarn.shMapReduce JobHistoryServer
对于MapReduce,默认无需特殊配置。Hadoop提供了一个管理任务执行历史的服务JobHistoryServer。按需启动即可。
mr-jobhistory-daemon.sh stop historyserver至此,一个基本的Hadoop集群已经启动完成。
集群管理环境 WebUI地址
Hadoop默认提供了查看集群状态的Web服务,在主节点上启动。默认端口如下。
HDFS集群管理,默认端口50070。http://master:50070/
ResourceManager管理,默认端口8088http://master:8088/
JobHistory 默认端口19888http://master:19888