Kafka在0.10版本推出了Stream API,提供了对存储在Kafka内的数据进行流式处理和分析的能力。
本文将从流式计算出发,之后介绍Kafka Streams的特点,最后探究Kafka Streams的架构。
什么是流式计算
流式计算一般被用来和批量计算做比较。批量计算往往有一个固定的数据集作为输入并计算结果。而流式计算的输入往往是“无界”的(Unbounded Data),持续输入的,即永远拿不到全量数据去做计算;同时,计算结果也是持续输出的,只能拿到某一个时刻的结果,而不是最终的结果。(批量计算是全量的:拿到一批数据,计算一个结果;流式计算是增量的:数据持续输入,持续计算最新的结果)
举个例子,统计电商网站一天中不同地区的订单量:
批量计算的方式:在一天过去之后(产生了固定的输入),扫描所有的订单,按照地区group并计数
流式计算的方式:每产生一个订单,根据订单的地区进行计数
流式计算相对于批量计算会有更好的实时性,倾向于先确定计算目标,在数据到来之后将计算逻辑应用到数据上。
流式计算和实时计算
流式计算的实时性较高,有时候容易和实时计算混淆。
流式计算对比的对象应该是批量计算,而实时计算对应离线计算。
流式计算强调的是计算的方式,而事实计算则强调计算结果的响应时间。
比如统计订单量,流式计算的方式是有一个计数,没来一笔订单就对这个计数加1。实时计算则是在在某个时刻计算一次当前时刻之前已经产生的所有订单量,比如在MySQL中执行一次Count操作。
Kafka Streams是什么
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka’s server-side cluster technology.
Kafka Streams是一个客户端类库,用于处理和分析存储在Kafka中的数据。它建立在流式处理的一些重要的概念之上:如何区分事件时间和处理时间、Windowing的支持、简单高效的管理和实时查询应用程序状态。
Kafka Streams的门槛非常低:和编写一个普通的Kafka消息处理程序没有太大的差异(得益于Kafka Streams是一个客户端类库且运行只依赖与Kafka环境),可以通过多进程部署来完成扩容、负载均衡、高可用(Kafka Consumer的并行模型)。
Kafka Streams的一些特点:
被设计成一个简单的、轻量级的客户端类库,能够被集成到任何Java应用中
除了Kafka之外没有任何额外的依赖,利用Kafka的分区模型支持水平扩容和保证顺序性
通过可容错的状态存储实现高效的状态操作(windowed joins and aggregations)
支持exactly-once语义
支持纪录级的处理,实现毫秒级的延迟
提供High-Level的Stream DSL和Low-Level的Processor API
Kafka Streams模型
Stream Processing Topology
stream是Kafka Streams中最重要的抽象:代表一个无界的、持续更新的数据集。stream是有序的、可重放的、容错的不可变数据记录的序列,其中的数据记录为键值对类型。
stream processing application是使用了Kafka Streams库的应用程序。它通过processor topologies定义计算逻辑,其中每个processor topology都是多个stream processor(节点)通过stream组成的图。
stream processor是processor topology中的节点,代表一个处理步骤:通过接收上游的processor的输入,应用计算逻辑,产生一个或多个输入到下游的processor。
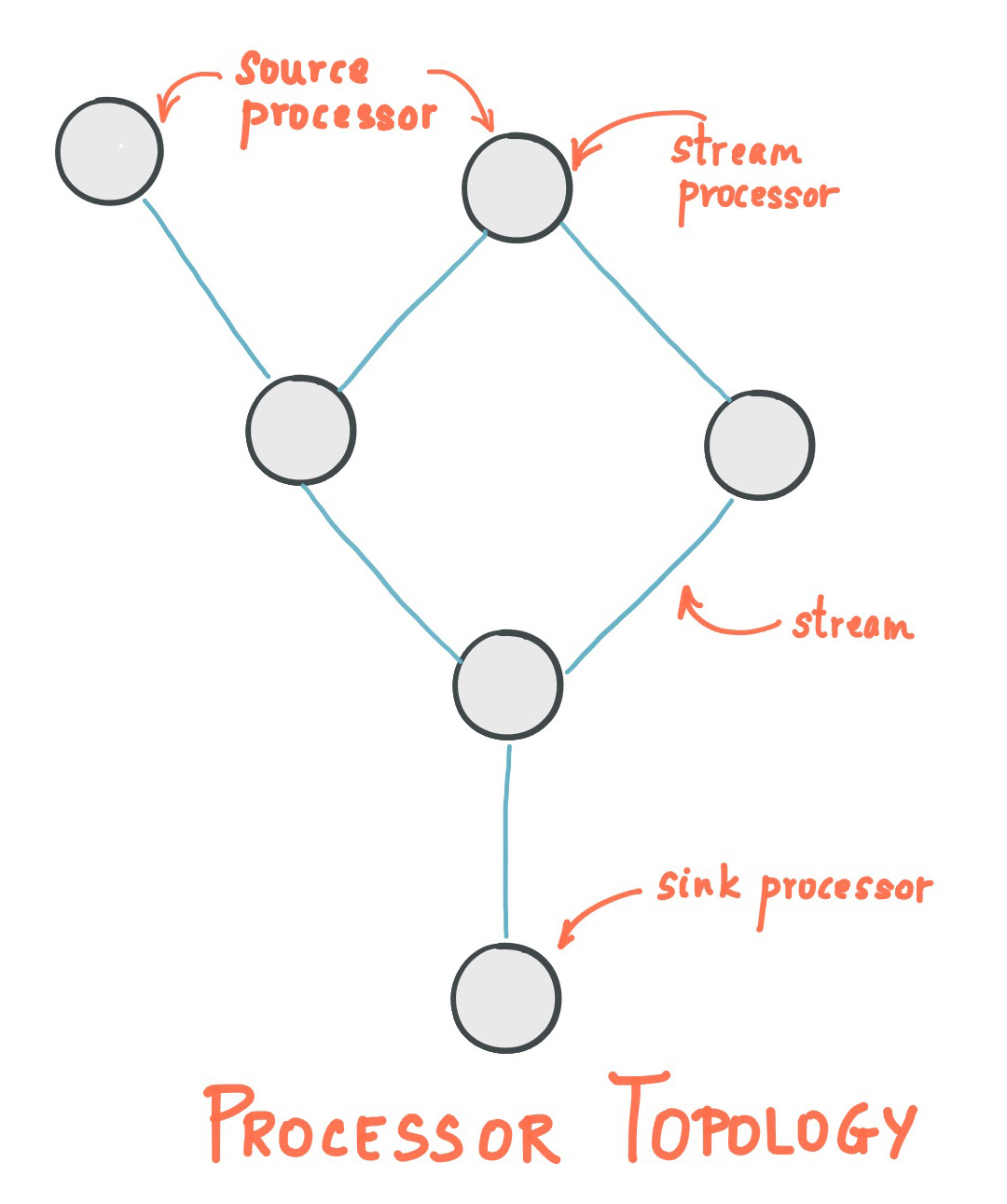
有两种特殊的processor:
source processor: 没有上游processor,接收来自一个或多个Kafka Topic的数据,处理并传递到下游的processor
sink processor: 没有下游processor,接收来自上游processer的数据,处理并写入到Kafka Topic中
Kafka Streams提供了两种定义stream process topology的方式:Kafka Streams DSL和Processor API。Kafka Streams DSL提供了基础的、通用的数据操作,比如map、filter、join、aggregations。Processor API定义和链接用户自定义的processor,并且和state store交互。
Time
流处理中一个关键的方面是时间的概念,以及它如何建模和整合。例如windowing操作是基于时间边界定义的。
stream中的一些时间:
Event time:事件发生的时间,产生在“客户端”。location change.
Processing time:Stream processing application处理时的时间。Processing time可能落后于Event time几毫秒或者几个小时、几天。如果数据没有被处理,那么就没有Processing time。
Ingestion time:数据存储到Kafka Topic的时间,同样落后于Event time。
Kafka Streams通过TimestampExtractor接口为每个数据记录分配一个时间戳。记录级的时间戳描述了stream的处理进展并被类似于window这样依赖于时间的操作使用。这个时间只在新数据到达后进行更新,称这个由数据驱动的时间为stream time。TimestampExtractor接口的具体实现给stream time提供了不同的语义,比如stream time可以是基于event time的,也可以是基于processing time的。
States
如果每一条数据的处理都是相互独立的,没有依赖关系的,那么stream processing不需要状态存储。但是,提供状态存储(state store)能给stream processing提供更多的可能性:比如进行join、group之类的操作。Kafka Streams DSL提供了这些能力。Kafka Streams中每个任务都嵌入了一个或者多个可以通过API访问的状态存储。状态存储可以是持久化的KV或者内存HashMap,也可以是其他的数据结构。Kafka Streams提供了本地state stores的容错和自动恢复。
Kafka Streams架构

Stream Partitions and Tasks
Kafka消息层为了进行存储和传输对数据进行分区;Kafka Streams为了处理数据而分区。在两种场景下,分区保证了数据的可扩展性、容错性、高性能等等。Kafka Streams使用了基于topic partition的partitions和tasks的概念作为并行模型中的逻辑单元。在并发环境行,Kafka Streams和Kafka之间有着紧密的联系:
每个stream partition是顺序的数据记录的集合,并且被映射到一个topic partition
stream中的每个data record对应topic中的一条消息(message)
数据记录中的keys决定了Kafka和Kafka Streams中数据的分区,即,如何将数据路由到指定的分区
应用的processor topology通过拆分成多个task来完成扩容。更具体的,Kafka Streams根据输入的stream partitions创建固定的task,每个task分配来自stream的一个分区列表。分配结果不会变更,所以tasks是应用程序固定的并行单元。Tasks可以根据分配的分区初始化自己的processor topology;它们还可以为每个分配的分区维护一个缓冲,并从这些记录缓冲一次一个地处理消息。作为结果,流任务可以独立和并行的处理而无需手动干预。
理解Kafka Streams不是一个资源管理器是非常重要的,它是一个类库,运行在stream processing application中。多个应用实例可以运行在同一个机器上,也可以运行在多个机器上,Tasks可以自动的分配到运行的实例中。分区和tasks的分配关系不会变更,如果应用实例“挂掉”,实例分配的任务将被自动的在其他的实例上重启并从同样的stream partition开始消费数据。
下图展示了两个task,每个task分配了stream的一个分区的场景:
(图中写入topic C的分区是不是画错了?Task0应该输出topic A p0和topic B p0的数据)
Threading Model
Kafka Streams允许用户配置应用实例中类库可以用于并行处理的线程数。每个线程可以执行一个或者多个task。下图中一个线程执行两个stream task:
启动多个stream线程或者实例,仅仅只是增加了topology,使他们并行处理不同的分区。值得注意的是这些线程之间不共享状态,无需协调内部线程。这使得通过多应用实例和线程去并行的运行topology变得非常简单。Kafka topic partition的分配通过Kafka的协调器完成,对Kafka Streams是透明的。
如上所述,Kafka Streams程序的扩容非常简单:仅仅只是多启用一些应用实例,Kafka Streams负责在应用实例中完成分区的task对应的分区的分配。
Local State Stores
Kafka Streams提供了state stores,可以用于stream processing application存储和查询数据,对于实现有状态的操作非常的重要。Kafka Streams DSL会在使用join()、aggregate()这种有状态的操作时自动的创建和管理state stores。
Kafka Streams应用中的每个task可能会嵌入一个或者多个state stores用于存储和查询数据。Kafka Streams提供了state stores的容错和自动恢复的能力。下图展示了两个stream task,每个task都有一个自己专用的state store。
状态存储是在本地的,Kafka Streams这块是如何做容错和自动恢复的呢?
Fault Tolerance
Kafka Streams的容错依赖于Kafka自身的容错能力。Kafka的partition提供了高可能用复制的能力,所以如果将Kafka Streams的数据存储在partition中那就自然的实现了容错。Kafka Streams中的task的容错实际上就是依赖于Kafka consumer的容错能力,如果task所在机器故障,Kafka Streams自动的在可用的应用实例上重启task。
对于每个state store,保持一个可复制的changelog Kafka topic用于跟踪state的任何变更。这些changelog topic同样是被分区的。change log的topic是开启压缩的,所以历史数据会被清除,避免数据无限制的增长。如果一个task所在的机器发生故障,task转移到另一个机器,Kafka Streams将通过change log重建local state store。整个失败处理的过程对用户来说是透明的。
注意,task初始化(或者重新初始化)的耗时通常主要取决于通过重播change log来恢复state store来的时间。为了减少恢复时间,用户可以配置他们的应用拥有一个备用的local states的副本(也就是说,一个state副本的完全拷贝)。当发生了一个task迁移,Kafka Streams试图将task分配到一个应用程序的实例上,这个实例上已经存在一个备用的副本用于最小化task初始化的时间消耗。
总结
Kafka Streams是一个类库,实现了流式计算的能力、除Kafka外无任何外部依赖、充分利用了Kafka的水平扩容和容错等能力
通过state store为状态计算提供了可能;通过replicated change log和log compact解决了state store的容错和数据膨胀的问题
基于offset的计算进度管理以及基于state store的中间状态管理为发生Consumer rebalance或Failover时从断点处继续处理提供了可能,并为系统容错性提供了保障
Kafka Streams适用于哪些输入和输出都存储在Kafka中的业务。类似的,如果在Message Queue的场景中有很多业务都接收来自MQ的消息,处理之后产生新消息投递到MQ中给下游业务处理,那么提供类似的一套Stream的机制将大大简化业务方的开发工作,提升效率(在没有Stream的情况下需要使用Consumer和Producer完成从MQ接收消息和投递消息到MQ,且需要将中间的过程串联起来;Stream的模式下用户则只需要关心自身的业务逻辑)。