EventBus 源码解析
这篇深度技术文章剖析了Android开发者常用的事件总线框架EventBus的内部工作原理。作者从Event、Subscriber、Publisher这些核心概念入手,逐步解析了EventBus的注册订阅与事件分发机制。 文章通过清晰的类关系图和核心类功能介绍,揭示了EventBus内部如何通过subscriptionsByEventType这个核心数据结构,高效地实现事件到订阅者的匹配。同时,详细说明了post事件后,EventBus如何根据订阅者声明的ThreadMode(如PostThread、MainThread、BackgroundThread、Async),智能地决定是在当前线程、主线程还是异步线程中执行事件处理函数,确保了线程安全。 对于想深入理解Android消息机制和组件解耦实践的开发者,这篇文章提供了一个关于如何设计一个优雅、高效的发布-订阅系统的清晰实现思路。
PHP empty和isset源码分析
作者从一个具体的PHP问题出发:`empty('00')` 到底返回 `true` 还是 `false`?他原本猜测 `empty()` 会将字符串 `'00'` 转换成数字进行判断,但觉得又不对。为了验证,他决定直接从源码一探究竟。 文章跟随作者的思路,首先发现 `empty()` 和 `isset()` 在操作码层面都调用了同一个函数 `ISSET_ISEMPTY_VAR`。顺藤摸瓜,最终定位到实际执行判断的核心函数是 `i_zend_is_true()`。 通过阅读这段精炼的源码,作者得出了明确的结论:`empty()` 在判断时并没有进行类型转换。对于字符串,它的判断逻辑非常直接——先检查字符串长度是否为0(即空字符串),若不是,则进一步检查是否长度为1且唯一字符为 `'0'`。只有这两种情况才会返回“空”(`true`),否则都返回非空(`false`)。 因此,对于 `'00'` 这样长度为2的字符串,它不满足上述任一条件,所以 `empty('00')` 的结果就是 `false`。而 `isset()` 则更简单,在变量未赋值时就直接返回了,根本不会走到这个判断逻辑。这个源码级的分析,清晰地解答了最初的那个疑问。
分布式存储Seaweedfs源码分析
这篇文章对分布式文件存储系统 SeaweedFS 0.67 版本的源码进行了一次深入的解剖。作者从其基于 Facebook Haystack 论文的架构思想出发,指出 SeaweedFS 实现了“青出于蓝而胜于蓝”的改进。 文章清晰地梳理了项目的核心模块,重点剖析了其两大支柱:拓扑管理与数据存储。在拓扑层面,详解了由 DataCenter、Rack、DataNode 构成的树状结构,这正是其管理分布式 VolumeServer 的核心。而在数据存储层面,则层层递进,解释了文件唯一标识 Fid 的构成(VolumeId, NeedleId, Cookie),并深入到 Volume 文件内部的布局——SuperBlock 与 Needle 的关系。特别值得一提的是,文中对 SuperBlock 中 TTL(Time To Live)功能的实现原理进行了拆解,阐述了如何通过 Volume 级别的超时标记与清理机制来优雅地实现文件的定时删除。 整体来看,这篇文章并未停留在功能介绍,而是直击代码,帮助读者理解 SeaweedFS 如何用简洁的设计实现高性能的对象存储,对于理解分布式存储系统的工程实现很有参考价值。
Gearmand异步处理就安全了吗?不!
这篇讲的是一个实际生产中遇到的Gearman异步处理陷阱。当团队使用Gearman作为中间件时,发现Gearmand进程会莫名卡住,将PHP请求长时间“Hold”住,即便设置了超时也无效,这对PHP的同步工作模式风险很高。 问题最终被定位到使用Gearman的 `addFunction` 注册任务时,如果指定了 `timeout` 参数,便可能随机复现。通过 `pstack` 工具观察发现,故障时Gearmand的工作线程数量会减少。文章通过分析版本变更与源码指出,从0.33版本起增加的Worker超时处理特性,在底层依赖的libevent 1.4.x(非线程安全)环境下,导致了 `event_base` 对象被跨线程错误操作,从而使得工作线程的事件循环意外退出。 解决方案是从源码层面修正这一问题,例如将发生跨线程调用的 `event_base_set` 方法中的操作对象进行调整。作者最终建议,通过将 `addFunction` 的 `timeout` 参数临时设为0,可以规避此问题。这篇分享对使用Gearman或类似基于libevent组件的团队有很高的参考价值,尤其是在排查无响应卡顿问题时。
php内核探索之zend_execute的具体执行过程
这篇文章从底层源码出发,剖析了PHP脚本引擎执行PHP代码的核心路径。它聚焦于引擎初始化的默认执行函数`execute`,并对其完整执行流程进行了逐行解读。 核心实现思路清晰展现:`zend_execute`本质上是个函数指针,指向`execute`函数。该函数首先为`zend_execute_data`分配并初始化执行上下文,包括CV变量表、临时变量空间以及保存当前执行状态,这类似于进程调度时的上下文保存。随后,进入一个无限循环,通过调用当前op指令的handler来驱动每一步操作,并根据handler的返回值(如跳转、函数调用)来控制流程。 文章的巧妙之处在于揭示了PHP虚拟机动态分派的关键机制。它详细解释了传入的`zend_op_array`结构体,特别是其`type`字段如何区分全局代码、用户函数和eval代码,明确了这些不同的代码块在执行层面本质上都是同一种操作数数组。最终,所有复杂的PHP逻辑都归结为对opcodes数组中每条指令handler的循环调用。 整篇文章用代码级的追踪,清晰展示了从`zend_execute`入口到单个操作码handler被调用的完整链路,是理解PHP运行时底层运作的扎实资料。
SSDB 源码分析 – 网络框架概述
这篇从SSDB重构后的模块化代码出发,聚焦其高度可复用的网络框架。作者首先指出SSDB网络协议虽简单且业务无关,能广泛应用于各类应用,但许多实现代码在解析报文时不够严谨,常误用`fgets()`等行级IO函数。随后,文章剖析了其多线程服务器框架的核心:通过`serve()`函数作为IO主线程管理连接与IO操作,并用`proc()`函数根据命令属性分发任务——或在主线程处理,或投入线程池。框架的巧妙之处在于,利用IO多路复用作为主循环,并通过名为`SelectableQueue`的结构,将线程间通信抽象为类似网络IO的逻辑,从而清晰高效地处理了主线程与工作者线程间的请求与响应传递。整个框架封装完善,几行代码即可构建并运行一个服务器。
SSDB源码分析 – 主从和多主同步原理解析
作者深入SSDB的内核,解析其主从与多主同步的设计哲学。核心思路是将主节点的所有写操作(Binlogs)在从节点重放,这与MySQL类似,但SSDB通过自动化解决了基础数据拷贝的痛点。 整个同步流程分为两个核心阶段:首先是**COPY状态**,此时从节点会像遍历链表一样自动复制主节点的全量数据。在此期间产生的新写入,会根据其在数据链表中的位置决定是立即同步还是留待后续处理。当游标移动到末尾,流程无缝进入**SYNC状态**,实现毫秒级的实时增量同步。 文章巧妙之处在于对细节的剖析:例如,通过为Binlog编号实现断点续传,并解释了`slaveof.type`配置为`mirror`是防止多主死循环的关键。它还澄清了一个常见误解——`slaveof.id`标识的是目标数据库而非物理机器,这使得数据迁移后同步关系能自动保持。 对于理解分布式存储的同步机制,或是面临具体配置问题的开发者来说,这篇从实现细节出发的分析提供了清晰的路线图。
深入剖析 redis replication 主从连接
这篇讲的是Redis主从复制机制的底层实现,特别是积压空间(repl_backlog)的设计与作用。 文章从主从架构的概述切入,指出其支持灵活的DAG拓扑以实现数据弱一致性。核心剖析聚焦于“积压空间”这一关键数据结构:它本质上是一个环形缓冲区,用于暂存数据变更记录。作者通过源码追踪,清晰展示了变更记录的写入路径:当命令执行修改了数据后,会经由 `call() -> propagate() -> replicationFeedSlaves()` 链路,最终被同时写入积压空间并分发给所有在线从机。 文章巧妙地解释了这种“双重写入”的设计意图:积压空间是为那些因故障断开连接的从机准备的。这些从机重连后,可以优先从这个环形缓冲区中获取断开期间错过的数据变更,进行高效的增量同步(部分同步),而非每次都进行全量同步。只有当断开时间过长,缓冲区无法覆盖时,才会退化为全同步。 通过对核心数据结构(如 `repl_backlog_size`, `repl_backlog_idx` 等)和关键函数的源码解读,文章深入浅出地揭示了Redis如何在保证实时同步的同时,优雅地处理节点故障恢复的场景,展现了其在工程实现上的细腻考量。
深入剖析 redis RDB 持久化策略
这篇讲的是 Redis RDB 持久化的底层实现。作者从 RDB 与 AOF 的基本概念切入,随后迅速深入核心,剖析了负责持久化 IO 操作的关键数据结构 `struct rio`。 文章的亮点在于对 `rio` 结构的拆解。它巧妙地通过函数指针(如 `read`、`write`)抽象了读写行为,并用一个 `union` 联合体统一了对内存缓冲区和文件的处理,使得一套代码能同时服务于内存缓存和磁盘文件两种场景,设计上颇具巧思。 接着,作者以 `rdbSave()` 函数为主线,通过代码注释的方式,清晰地勾勒出整个 RDB 写文件的流程:从创建临时文件、初始化 `rio` 结构,到遍历每个数据库、写入操作码和数据项。这个过程不仅解释了数据是如何被序列化到磁盘的,也揭示了 BGSAVE 等后台操作的基础——主进程 `fork` 出子进程来执行这个主逻辑,从而避免阻塞服务。 对于想了解 Redis 如何将内存数据“快照”到硬盘的开发者而言,这篇文章提供了一个从数据结构到执行流程的清晰视角。
Django 源码小剖: Django ORM 查询管理器
这篇讲的是 Django ORM 中 `Book.objects` 这类查询入口背后的精巧设计。我们平时写 `Book.objects.filter()` 只图方便,但作者从源码出发,揭示了这行简单代码背后隐藏的机制。 文章首先点明,`objects` 并非 Model 类自带的属性,而是在 Django 启动时,通过 `ensure_default_manager` 函数动态“挂”上去的。真正的查询逻辑由 `Manager` 类承担。 但更巧妙的是 Django 的“保护技法”:`objects` 属性实际上是一个 `ManagerDescriptor` 描述符的实例。它利用 Python 的描述符协议,在 `__get__` 方法中判断访问者是类还是类实例。如果误在对象实例上调用 `book_obj.objects`,会直接抛出 `AttributeError`,确保了语义正确——查询只能从“类”这个集合概念发起,而非从单个数据实例。 作者通过剖析这一层包装,清晰地展现了 Django 如何在工程细节上贯彻设计原则,让 ORM 接口既简洁又严谨。他在 GitHub 上维护的 Django 源码注释项目,也为想深入探索的开发者提供了很好的路径。
memcached 源码阅读笔记
这篇讲的是作者深入阅读 memcached 源码后梳理出的核心流程。作者从程序的入口函数 `main()` 出发,剖析了 memcached 如何基于 libevent 构建起高效的事件驱动模型。初始化过程涉及事件中心、内部数据结构、空闲连接池以及工作线程的创建与配置。 文章重点分析了 memcached 两种可配置的服务模式:UNIX 域套接字与 TCP/UDP。前者在本地通信中性能更优,后者则提供了更通用的网络接入能力。两者通过注册 `event_handler()` 回调来处理客户端连接。 在多线程协作方面,文章揭示了一个巧妙的设计:每个工作线程拥有独立的连接队列(CQ)和 libevent 事件中心,并通过创建读写管道进行线程唤醒。主线程通过 `dispatch_conn_new()` 将新连接分发到指定线程的队列,工作线程则监听管道事件,按需取出并执行任务。这种基于事件驱动和管道通信的线程调度机制,保证了高并发下的处理效率。 作者从全局到细节,清晰展现了 memcached 如何用简洁的 C 代码,借助 libevent 实现了一个高性能、多线程的网络服务框架。
OpenStack Swift源码导读之——业务整体架构和Proxy进程
这篇文章深入剖析了OpenStack Swift对象存储的业务整体架构与Proxy进程的实现细节。作者从Swift的源码目录结构入手,清晰地解读了proxy、account、container、object等各业务进程的职责划分。 重点在于Proxy进程的业务处理逻辑。文章指出,理解其基于PasteDeploy的堆栈式WSGI架构是关键,每一层分工明确,最外层处理异常。Proxy进程通过解析请求URI和方法来识别资源类型,并借助控制器进行分发。其核心路由机制依赖于一致性哈希环,作者通过具体代码段(如get_nodes、get_part函数),展示了如何通过哈希计算将请求映射到特定的物理节点集合。 此外,文章还揭示了Swift在保证数据高可用性方面的设计:通过引用NWR原则(如3写2读),并在make_requests等公用方法中实现“法定人数”判定,确保了分布式环境下写操作的可靠性。整个导读将抽象的架构设计与具体的代码实现相结合,为读者理解Swift内部如何协调请求、定位资源与维护数据一致性提供了清晰的路径。
通过call_usermodehelper()在内核态执行用户程序
这篇讲的是如何在 Linux 内核中“跨界”执行用户空间的程序。作者从内核开发者常遇到的需求出发,介绍了 `call_usermodehelper()` 这个内核API。 文章指出了它的核心作用:让运行在内核态的代码(比如模块或驱动)能够主动启动并执行一个用户空间的可执行文件或系统命令,就像在 shell 里敲命令一样。作者还提到了一个关键的实现细节:这个函数最终会调用内核的 `do_execve()`,这和用户态的 `execve()` 系统调用在底层“殊途同归”,但调用路径和上下文完全不同。 为了说明如何使用,文章给出了一个加载函数的代码片段示例,演示了调用该API的基本结构。对于需要在内核逻辑中动态触发外部脚本或工具进行日志收集、环境配置等场景,这个接口提供了一条直接通道,理解它有助于编写更灵活的内核模块。
libcurl中使用curl_easy_getinfo 产生段错误分析
这篇文章从一个实际的开发案例出发,分享了在 libcurl 中使用 `curl_easy_getinfo` 函数时遇到的隐蔽陷阱。作者在编写 HSF 代理程序时发现,将 `CURLINFO_RESPONSE_CODE` 的返回值写入 `int` 类型变量会导致程序段错误,而使用 `long` 类型则一切正常。 问题的根源在于 `curl_easy_getinfo` 的实现采用了可变参数机制。库内部会按照 `long*` 类型来接收并写入数据,而编译器并不会检查调用者传入的指针类型是否匹配。在 64 位系统中,`long` 类型通常为 8 字节,`int` 为 4 字节,这导致函数调用时向较小的栈空间写入了过多数据,从而破坏了栈帧,引发了段错误。作者通过一段模拟代码清晰地复现并验证了这一过程。 文章的价值不仅在于指出了这个具体的 API 使用陷阱,更提醒开发者在面对 C 风格可变参数函数时需格外谨慎。类型声明的一字之差,在特定平台上可能演变成难以调试的内存破坏问题,这要求我们对底层数据模型和函数契约保持清晰的认知。
深入分析Volatile的实现原理
这篇技术分析从Java内存模型对Volatile的定义出发,深入到x86处理器架构层面,揭示了其保证共享变量可见性的硬件实现机制。 文章通过分析JIT生成的汇编代码,指出Volatile写操作会触发带有Lock前缀的指令。这条指令会引发两个关键动作:强制将当前处理器的缓存行写回系统内存,并使其他处理器中该地址的缓存失效。这本质上是利用了处理器的缓存一致性协议(如MESI)和“缓存锁定”机制,以确保修改的原子性和全局可见性。 更巧妙的是,文章介绍了Java并发大师Doug Lea在JDK7中利用Volatile变量进行性能优化的实战案例。在LinkedTransferQueue中,他通过将队列头尾节点填充至64字节(一个缓存行的宽度),避免了它们因被读入同一缓存行而在多核处理器下相互锁死,从而显著提升了高并发下的出入队效率。文章最后也客观指出,这种追加字节的优化并非万能,需结合处理器缓存行大小与变量访问频率来决策。
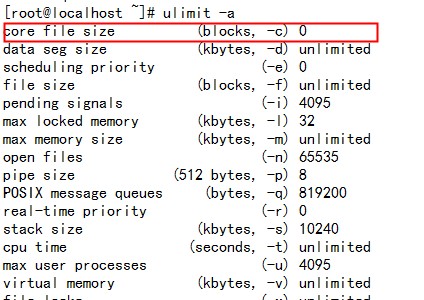
怎样用core文件调试你的linux程序?
这篇讲的是如何配置Linux系统,让它能在程序异常崩溃时自动生成核心转储(core dump)文件,从而方便你找出程序崩溃的具体原因。 作者从默认Linux禁止生成core文件这个常见限制出发,一步步演示了解锁方法。核心是使用`ulimit -c unlimited`命令,但文章也特别指出了它的临时性——设置仅对当前会话有效,重启或重登就会失效。如果想要更持久的配置,可以修改`/etc/profile`,不过作者也留下了思考:为什么不推荐这样做呢? 更深入的配置在于控制core文件“生在哪里”和“叫什么名字”。文章详细讲解了通过编辑`/etc/sysctl.conf`文件,设置`kernel.core_pattern`参数来实现。例如,将核心文件统一生成到`/tmp`目录,并使用包含程序名、进程ID、信号值等信息的规则来命名,这对于同时调试多个程序非常方便。 最后,文章点明了核心文件的归宿:使用强大的gdb调试器载入这个文件,就能回溯程序崩溃现场,定位问题代码。整个流程非常实用,是每个Linux开发者都应该掌握的调试技巧。
Jetty线程“互锁”导致数据传输性能降低问题分析
这篇讲的是在Jetty 7.2.1这个特定版本中,一个会导致数据传输性能降低的“互锁”问题。作者从Jetty经典的NIO异步反映器模型入手,分析了主线程(selector)与子线程(工作线程)之间的一种微妙配合失误。 问题的核心在于,当子线程遭遇网络拥塞、缓冲区写满时,它会进入阻塞状态并向主线程注册一个内部事件,等待拥塞解除的通知。然而,主线程的select循环在等待selector的网络事件时,可能并未及时轮询和处理这些内部事件,导致子线程无法被唤醒,形成“互锁”,拖累了整体性能。 文章通过拆解具体的代码逻辑,清晰地展示了这种线程间交互的瓶颈点。最终,作者指出了相应的解决或规避思路,比如合理设置超时参数,以帮助开发者在类似场景下优化配置,避免性能陷阱。
linux内核研究笔记(一)内存管理 – page介绍
这篇讲的是 Linux 内核内存管理中最基础的数据结构——`struct page`。作者以一名服务器程序员的视角,从对“虚拟内存”的好奇出发,深入内核底层,剖析了物理内存管理的核心。 文章首先展示了 `page` 结构体的关键字段,并指出它是内核描述物理内存页的最小单元。核心在于,这片物理页在不同场景下被赋予不同角色:作为页缓存(`mapping` 域)加速文件IO,作为私有数据(`private` 域)用于缓冲或交换,或作为页表映射支撑用户空间的 `malloc`。 作者进一步通过宏定义,解释了页帧号(pfn)与 `page` 指针、物理地址、内核逻辑地址之间的转换机制。比如 `pfn_to_page` 本质上是操作全局数组 `mem_map`,巧妙地将连续的物理内存抽象为可索引的对象。文章还厘清了“内核逻辑地址”与“内核虚拟地址”的区别,并点明在 x86_32 架构下 `PAGE_OFFSET` 的由来。 理解 `page` 结构是窥探内核如何管理伙伴系统、slab分配器乃至整个虚拟内存系统的钥匙。这篇笔记从最底层的数据结构切入,为后续理解更复杂的内存管理机制打下了坚实基础。
Python程序的执行原理
这篇讲的是Python代码从源文件到运行背后的核心机制——字节码与虚拟机如何协同工作。文章从最简单的“Python先把代码编译成字节码”这一概述出发,层层深入,带我们看清了执行过程的每个关键环节。 作者详细拆解了字节码在Python内部的具体形态——PyCodeObject对象,并剖析了其结构体定义,如co_code、co_consts等字段如何承载代码信息。对于开发者日常可能遇到的.pyc文件,文章也理清了它的生成时机(模块import时)与Python的加载更新策略,解开了不少常见疑惑。 文章的精彩之处在于将理论落地到可操作的层面。它展示了如何利用内置的compile函数和dis模块,去实际“解剖”一段代码对应的字节码指令序列,让抽象概念变得可视、可调试。最后,文章将视角拉升到虚拟机执行层面,通过类比X86的栈帧,讲解了Python如何通过PyFrameObject管理函数调用和作用域,完整模拟了一个程序的运行世界。 整篇文章就像一份精心绘制的内部结构蓝图,不仅告诉你Python“怎么做”,更展示了它是“如何做到”的,非常适合希望突破语法层面、理解Python执行本质的开发者。
FUSE源码剖析
这篇讲的是如何通过源码剖析来理解FUSE(用户空间文件系统)的内部工作原理。作者以FUSE-2.9.2版本的代码为基础,没有停留在概念介绍,而是直接切入核心,详细拆解了一个文件写操作在内核与用户空间之间完整往返的8个步骤。 文章清晰地梳理了从应用层发起write系统调用开始,请求如何经由VFS层传递给FUSE内核模块,被放入请求队列并等待,再到用户空间的守护进程轮询获取请求、执行实际操作,最后将结果同步返回内核的整个链条。这个视角生动展示了FUSE作为“桥梁”的实现机制。 为了支撑流程讲解,文章系统地介绍了内核侧与用户侧的关键数据结构,如管理通信连接的fuse\_conn、代表单次请求的fuse\_req等,勾勒出了FUSE框架的数据骨架。此外,文章还剖析了FUSE内核模块的加载注册过程,以及用户态程序通过mount命令将自定义文件系统挂载到内核的流程,从底层揭示了用户态文件系统得以运行的根基。 通过这样自顶向下与自底向上结合的剖析,文章将FUSE看似复杂的跨空间协作,还原为一组清晰的数据结构和函数调用,为理解这类“中间件”的设计思想提供了绝佳范例。