HAProxy的event_accept函数源码分析
这篇讲的是HAProxy核心组件event_accept函数的源码深度剖析。面对HAProxy复杂庞大的代码库,作者直接指出其函数动辄数百上千行的“代码风格问题”,并选择以event_accept函数为例,通过主动重构来拆解分析,让逻辑脉络清晰起来。 文章将函数执行流程系统性地拆解为六个关键步骤:从接收连接后,首先检查连接数与文件描述符是否超限;接着设置客户端socket的非阻塞、TCP优化等属性;然后从内存池分配新会话(session)并初始化状态;再分配处理任务(task)并绑定回调函数;最后分别配置会话的客户端与服务端流接口(stream interface),为后续数据转发做好准备。 作者不仅逐步解读了每个步骤的代码逻辑,更通过调整代码顺序和重组变量,呈现了一个更清晰、更模块化的实现思路。这种分析方式让读者能跳过原始代码的冗余,直接抓住HAProxy处理新连接时,在资源分配、状态初始化与任务绑定方面的核心设计逻辑。
kmemcache源码浅析
这篇讲的是memcache的Linux内核移植版kmemcache的源码实现。作者深入分析了这个不走寻常路的高性能缓存项目,重点剖析了它如何摒弃了常见的epoll通知机制,转而利用网络数据包 skb 的回调函数,实现了更细粒度的 packet 级调度。 文章的核心在于揭示kmemcache独特的网络模型设计:一个dispatcher(调度器)与多个worker(工作线程)协同工作。其中dispatcher专门负责处理TCP和Unix域套接字,并将新建的连接分配给特定的worker;而所有的UDP请求也由这些worker直接处理。 在实现细节上,文章拆解了用户态守护进程umemcached与内核模块kmemcache.ko之间,如何通过Netlink机制完成启动参数传递等关键交互。作者结合具体的代码结构(如cn_entry、cn_queue),清晰地展示了“请求-应答”的同步通信流程,以及其中涉及的序列号管理和回调处理等巧妙设计。 整体来看,这是一篇扎实的内核级源码剖析,它不仅解释了kmemcache“做了什么”,更细致地拆解了它是“怎么做到的”,对于想理解Linux内核网络子系统优化或高性能缓存实现的读者来说,提供了非常具体的参考。
一个绝妙的 exploit
这篇讲的是 Linux 内核一个经典的提权漏洞分析。漏洞源于 `perf_swevent_init` 函数中,`event_id` 被定义为带符号的 `int`,而后续检查仅校验了其上界。当传入一个高位为1的负数时,该值能绕过检查并导致 `perf_swevent_enabled[]` 数组越界访问。 作者详细剖析了 exploit 的巧妙思路:利用数组越界,分别对一个内核地址和一个用户空间地址(通过精心计算 `mmap` 得到)执行原子加一和原子减一操作,从而探测出数组基地址。更精妙的是,作者选择了修改中断描述符表(IDT)中某个条目的高32位偏移地址。这个地址原本固定为 `0xffffffff`(内核空间),通过一次原子加一,它被变为 `0x00000000`,从而指向了用户空间。如此一来,触发对应的中断(`int 0x4`)便会跳转到攻击者预先布置好的、用于修改进程 uid/gid 的用户代码,最终获得 root shell。 整个攻击链条的核心,就是一个看似微小的类型符号不一致问题,经过层层推导和内存布局计算,最终转化为强大的攻击能力,令人印象深刻。
malloc()之后,内核发生了什么?
作者从一个常见的用户空间操作出发,即进程调用 `malloc()` 后尝试访问内存,一路追踪到内核空间的真实发生过程。文章的核心在于揭示,用户感知到的“内存分配”在内核层面主要通过 `brk` 系统调用来实现,其背后是一套从修改堆描述符到最终响应缺页异常的精密机制。 讲解路径非常清晰:首先,`malloc()` 会触发 `brk` 系统调用,通过 `SYSCALL_DEFINE1(brk,...)` 服务例程来调整进程的堆边界。文中展示了该例程如何检查资源限制、对齐地址,并根据是扩大还是缩小堆,分别调用 `do_brk()` 或 `do_munmap()`。 文章的巧妙之处在于指出,此时内核通常并未立即分配物理内存。`do_brk()` 的核心工作是在进程的虚拟地址空间中分配或合并一个线性区间(VMA),为后续可能的操作“预留地盘”。真正的魔法发生在第二步:当进程首次访问这块新地址时,CPU 会因页表项无效而触发缺页异常。文章接着深入异常处理流程,从 `page_fault` 入口,到 `do_page_fault()` 判断异常类型,最终由 `handle_mm_fault()` 接手。 在 `handle_mm_fault()` 中,内核才开始真正“分配”物理内存——它确保页目录结构完整,然后调用 `handle_pte_fault()` 完成页框的分配与映射。整个过程生动地体现了 Linux 内存管理中“延迟分配”的核心思想:先给予虚拟承诺,待实际使用时再兑现物理资源,从而优化了内存使用效率。这对于理解内存分配的全链路至关重要。
fatcache源码浅析
这篇讲的是Twitter开源的缓存服务fatcache,可以把它理解为一个“SSD版的Memcached”。作者从其源码出发,剖析了它如何用有限的内存索引,去管理大容量的SSD存储。 文章详细解读了fatcache的核心设计。它使用通用的队列(generic queue)来管理资源池,底层则采用了经典的slab allocator内存模型。作者拆解了slabclass、slab和item等关键结构,并说明了fatcache如何在内存中用哈希表快速索引key,而实际的value数据则可能存储在内存或磁盘的slab里。 最精巧的部分在于其读写与淘汰机制。为了适配SSD,fatcache设计了一套基于FIFO的淘汰策略。在写入时,它能将内存中的slab成片地交换到磁盘,巧妙地将随机写转化为顺序写,提升了IO效率。对于删除操作,它只在索引层面标记删除,而不立即修改SSD数据,等待后续自然淘汰,这种设计充分避免了不必要的随机写入。 整个设计体现了对硬件特性的深刻理解,用相对简单的队列和slab管理,在缓存层实现了高效的数据存取。
gen_tcp接收缓冲区易混淆概念纠正
这篇讲的是 Erlang/OTP 中 `gen_tcp` 模块几个缓冲区参数之间的常见混淆。很多开发者看到 `buffer`、`sndbuf` 和 `recbuf` 这三个选项时容易困惑:它们到底是什么关系?文档的简要说明往往不足以理清头绪。 作者选择直接深入 C 驱动层源码(`inet_drv.c`)来寻找答案。通过分析 `inet_set_opts` 函数的实现,文章揭示了核心事实:`sndbuf` 和 `recbuf` 设置的是内核 Socket 层的发送与接收缓冲区大小,这符合常规理解。而 `buffer` 选项则完全不同,它设置的其实是 Erlang VM 内部、应用层用于暂存从 Socket 读上来的原始数据的缓冲区大小提示(`desc->bufsz`)。 文章一个巧妙的发现是,源码中存在自动调整逻辑:当显式设置 `sndbuf` 或 `recbuf` 后,`buffer` 的值会被自动更新为两者中的较大值,以确保应用层缓冲区足够容纳内核传上来的数据。但其影响范围仅限于接收路径——因为发送数据可以利用队列,无需类似的额外缓冲。 通读全文,它厘清了一个关键结论:这三个参数分属不同层级,`buffer` 专注于控制 Erlang 侧接收数据的临时缓存大小,其默认值和动态扩容策略都围绕接收场景设计,而不直接影响内核的 Socket 缓冲区。对于需要精细调优 TCP 通信性能的开发者,理解这层区别至关重要。
get_adjacent_post函数PHP源码阅读笔记
这篇文章解读了WordPress中`get_adjacent_post`函数的实现。虽然函数有效代码仅70行左右,但作为获取相邻文章的核心逻辑,它包含了数据库查询构建、参数处理和缓存优化等典型Web后端设计思路。 作者从函数签名切入,清晰拆解了三个参数的作用:是否限定相同分类、排除特定分类、以及指定获取前一篇还是后一篇。函数的三种返回状态也被明确点出,这直接反映了代码的健壮性设计。 核心实现部分展示了如何动态构建SQL查询。特别值得注意的是两点:其一,代码利用`$wpdb`全局变量进行数据库操作,这是WordPress封装的标准方式;其二,通过`apply_filters`为查询的JOIN、WHERE和ORDER BY部分留出了扩展点,允许主题或插件自定义查询逻辑,这是WordPress强大灵活性的体现。 最后,函数引入了对象缓存机制,通过`wp_cache_get`和`wp_cache_set`避免重复查询数据库,在频繁调用时能显著提升性能。这些细节让一个看似简单的函数变得值得细读。
深度剖析告诉你irqbalance有用吗?
这篇深度技术剖析探讨了irqbalance这个中断平衡守护进程的实际价值。文章从“是否有必要开启它”这一实际运维问题切入,通过解读源码揭示了irqbalance的工作机制:它每10秒循环收集/proc/interrupts的中断分布数据,并根据设备类型(如网卡、存储设备)与CPU拓扑结构,动态计算并调整中断的CPU亲缘性。 作者指出,在特定高性能场景下(如应用已绑定CPU核),irqbalance的自动调整可能并非最优甚至不必要,因此需要理解其原理来做出正确取舍。文章深入解析了irqbalance如何利用SMP Affinity接口、区分中断类型在Package、Cache或Core级别进行平衡,将原本黑盒的守护进程逻辑清晰展现出来。对于需要精细调优系统中断分布的工程师而言,这些底层细节是做出判断的关键依据。
Memcached二三事儿
这篇讲的是作为NoSQL“老兵”的Memcached。尽管Redis等后起之秀势头强劲,Memcached在许多项目中依然不可或缺。文章没有停留在“要不要学”的讨论,而是直接深入Memcached的核心——Slab内存分配机制。作者用了一个生动的比喻来解释Page、Slab和Chunk之间的关系,指出早期版本中内存无法跨Slab调配的痛点,并介绍了新版本通过slab_reassign参数实现的“Page改嫁”机制。 文章还触及了Memcached在实际应用中的典型挑战。例如,为应对缓存失效瞬间的“惊群效应”(stampeding herd),作者依次讨论了主动更新、加锁、柔性过期等方案的利弊,并最终引入了通过Gearman进行异步任务分发的更稳健的解法。此外,文中提及的Twemcache对Memcached的改进,也从侧面反映了技术在实际生产中的演进。 对仍在使用或需要深入理解Memcached原理的工程师来说,文章对内存管理细节的剖析和对常见坑点的梳理,依然具有很强的实用参考价值。
libmemcached的MEMCACHED_MAX_BUFFER问题
这篇讲的是作者在服务监控中发现一个异常:使用libmemcached向Memcached写入约10KB数据时,延迟竟高达7ms。为定位问题,作者分别用shell脚本(通过nc直接发送命令)和C++程序(调用libmemcached API)进行测试。结果出人意料——更“底层”的C++版本耗时远超shell脚本。 通过ltrace跟踪,作者发现数据发送很快,但等待服务端响应的时间很长。深入排查后,根源浮出水面:libmemcached库内部定义了一个名为`MEMCACHED_MAX_BUFFER`的常量,其值为8196字节。对于超过此大小的数据,库会将其拆分为两次`write`系统调用发送。这种拆分机制导致了显著的网络往返开销,成为了性能瓶颈。 解决方法相对直接:重新编译libmemcached,将该常量值从8196调大至81960。修改后,延迟从7ms锐减至1ms左右。作者也分析了服务端日志,确认时间主要消耗在连接状态切换的等待上。这个案例生动说明了第三方库中某个未公开的硬编码限制,可能对性能产生难以预料的影响。
libev ev_io源码分析
这篇深入分析了libev事件库中负责I/O事件监听的ev_io组件。作者从项目实践中的疑问出发,首先梳理了libev的核心抽象:所有watcher的基类`ev_watcher`,以及统一管理所有watcher状态的`ev_loop`结构。 文章重点剖析了ev_io的实现机制。它解释了ev_io如何“继承”`ev_watcher_list`以实现链表管理,并与一个名为`ANFD`的结构(用于映射文件描述符与事件链表)协同工作。对ev_io最关键的几个操作——添加、执行回调和删除——进行了流程拆解。 例如,添加watcher时并非立即调用`epoll_ctl`,而是先记录到一个待处理队列中,在下次循环的`epoll_wait`前才批量修改内核事件,这是一个精巧的优化。唤醒与回调过程则展示了如何根据epoll返回的结果,从事件链表中找到匹配的watcher并触发其回调函数。 整体来看,这篇文章清晰地展示了libev如何用简洁的C结构实现高效的事件驱动模型,对于想理解事件循环底层机制,特别是I/O多路复用与应用层封装之间交互的开发者来说,提供了很好的实现视角。
TermRangeQuery源码解析
这篇讲的是Lucene中`TermRangeQuery`的源码实现。作者从它如何处理一个范围查询出发,揭示了其核心机制:在重写Query树时,会根据查询范围匹配到的Term数量动态决定后续策略。 如果范围内的Term和关联文档较多,为避免性能问题,它会被包装成`ConstantScoreQuery`,通过`Filter`的方式直接获取并遍历文档ID集合。反之,如果Term数量不多,它会被拆解成多个独立的`TermQuery`,用`BooleanQuery`合并结果。这个自动选择的过程,体现了性能与精度之间的权衡设计。 文章进一步通过源码,清晰地展示了从Query树到Weight树,再到Scorer树的生成链路,最终如何遍历并收集文档ID。整个实现的关键在于,通过`MultiTermQueryWrapperFilter`统一了两种路径,将范围查询的最终执行收敛为高效的文档ID集合迭代,巧妙地规避了生成大量Clause可能带来的问题。
BLCR(Berkeley Lab Checkpoint/Restart)介绍及Checkpoint架构剖析
这篇讲的是进程检查点(Checkpoint)工具BLCR的核心架构剖析。作者从`cr_checkpoint`命令的用法出发,深入讲解了BLCR如何通过特定信号(64号实时信号)与内核模块协作,来实现对进程状态的“快照”保存。 文章重点剖析了用户态工具与内核模块通过`/proc`文件系统交互的机制。核心在于,BLCR需要为目标进程预先注册一个专用的信号处理函数。为此,它设计了两种等效的接入方式:一种是使用`cr_run`脚本启动程序,通过`LD_PRELOAD`预加载`libcr_run.so`库;另一种是在编译时直接链接`libcr`库。文章进而深入内核,解析了检查点请求(`cr_chkpt_req`)的构建过程,以及内核如何通过创建任务对象和进程请求对象来跟踪目标进程树,并最终完成内存的转储。 最巧妙的是,文章对比了两种接入方式在底层实现上的微妙差异:链接`libcr.so`的程序在信号处理函数中会通过两次`ioctl`调用来完成操作并通知完成;而通过`cr_run`启动的程序则使用汇编实现的信号处理函数,一次性完成转储并依赖一个特殊标志(`_CR_CHECKPOINT_STUB`)在内核侧直接触发完成流程。这种对源码细节的深挖,揭示了BLCR在兼容性和设计灵活性上的考量。
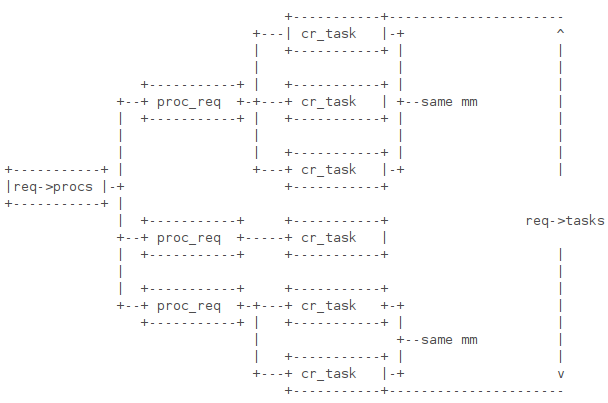
Yii框架base包代码分析
这篇讲的是作者对Yii框架base包的源码深度剖析。作者从一次周日的源码学习出发,借助Visual Paradigm工具,绘制出了该版本框架核心类的UML结构图。 通过类图的面积分布,作者指出整个框架的基石是CComponent、CModule、CApplication和CModel这四个类。尽管在上层开发中几乎直接接触不到它们,但它们如同“水面之下的引擎”,支撑着整个框架的运行。 文章重点剖析了CComponent这个“元老”类。作者梳理发现,其方法主要围绕魔术方法、Behavior(行为)和Event(事件)三类展开,这恰好揭示了Yii组件模型的三大支柱:通过魔术方法实现的属性成员、事件驱动机制以及可扩展的行为注入。这些底层设计,正是Yii框架灵活性与扩展性的源头。
urllib2源码解读三(探索OpenerDirector的add_handler)
这篇讲的是 urllib2 源码中 OpenerDirector 的 add_handler 方法如何实现 handler 的自动分类。文章接续了之前对 build_opener 的探讨,深入到 add_handler 的内部,揭示了它并非简单存储,而是根据每个 handler 实例所具有的方法,进行智能归类。 核心的实现思路非常巧妙:它不依赖显式的类型标识,而是通过解析 handler 方法名的结构来动态分类。具体来说,代码会遍历 handler 的所有方法,检查方法名是否包含特定模式,例如 `http_error_404` 或 `https_open`。它以第一个下划线为界,前半部分是协议(如 http、https),后半部分是条件(如 open、error_301)。根据这些解析出的信息,handler 会被分别注册到 `handle_open`、`handle_error`、`process_request`、`process_response` 这四个核心字典中,使得后续的网络请求调用链能高效、准确地匹配到对应的处理器。 这种基于“约定优于配置”的动态注册机制,让 handler 的功能与协议、状态码紧密绑定,既保持了扩展的灵活性,又确保了内部调用的有序性,是 Python 标准库设计中的一个典型范例。
urllib2源码解读二(简单的urlopen)
这篇文章从大家最熟悉的 `urllib2.urlopen('http://python.org')` 这行代码出发,带我们潜入Python标准库的源码内部,探索一个简单HTTP请求背后的构建机制。 作者揭示了一个巧妙的设计:`urlopen` 在首次调用时,并不会重复创建连接对象,而是通过 `build_opener` 函数构建一个全局的 `_opener` 对象。后续的所有请求都复用这个对象,从而避免了频繁初始化的开销。这个 `_opener` 本质上是 `OpenerDirector` 的实例,它像一个项目经理,内部通过几个关键的字典(如 `process_request`、`handle_open`、`process_response`)来管理众多功能各异的“处理器”(handler)。 文章重点剖析了 `build_opener` 函数的运作:它先初始化一个 `OpenerDirector`,然后将一系列默认的 handler 类(如 `ProxyHandler`、`HTTPHandler` 等)注册进去。整个过程清晰地展现了 urllib2 高度模块化的架构——通过组合不同的 handler 来构建功能强大的 opener,使得网络请求的处理流程灵活且可扩展。这让读者不仅能看懂代码,更能理解其设计哲学。
urllib2源码解读一(开篇)
作者从某个午饭后刷微博的感悟出发,决定深入阅读Python中一个超高频使用的模块——urllib2的源码。这篇文章是该系列的开篇,为读者勾勒了整个urllib2工作流的全景图。 文章重点剖析了三个核心对象:负责构建处理器的`build_opener`、作为流程调度中心的`openerdirector`,以及封装请求细节的`request`对象。其巧妙之处在于`openerdirector`的设计,它利用两个字典(`process_request` 和 `process_response`)对不同协议的Handler进行分类管理,形成了一条清晰的处理链。作者也点出,这背后借鉴了经典的Command设计模式。 在补充说明中,作者用更直观的语言复述了从`urllib2.urlopen(url)`调用开始的完整流程:OpenerDirector被构建并注入一系列Handler,生成的Request对象决定请求方法(GET/POST),并最终经过Handler链的处理返回一个类似文件对象的Response。这种从实例到抽象、再回归实例的解读方式,让复杂的框架设计变得易于理解。 作者阅读源码的初衷,是想透彻掌握这个日常工具,并从其设计中汲取营养。对于想理解HTTP请求处理机制或学习框架设计的开发者来说,这篇拆解提供了一个很好的思维起点。
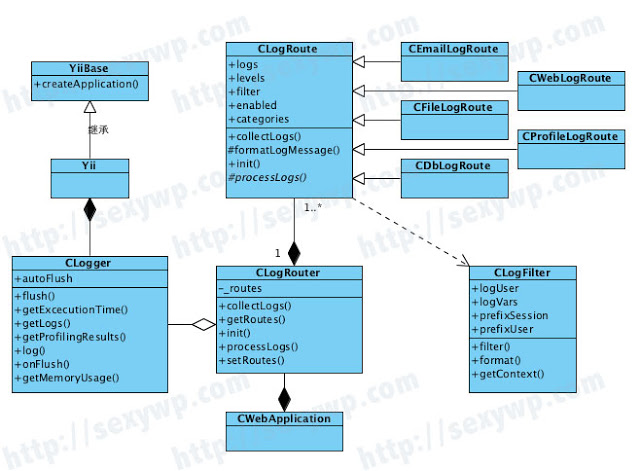
Yii框架的Log系统的分析
这篇讲的是 Yii 框架中日志(Log)系统的内部实现。作者从 logging 目录下的源代码出发,梳理了这个灵活且强大的日志模块是如何工作的。 文章的核心在于剖析其解耦设计:负责“打日志”的 CLogger 和负责“记录日志”的 CLogRouter 是两个独立的对象。CLogger 充当生产者,通过单例模式提供全局调用接口,并将日志信息存入一个内存缓冲区。当缓冲区满时,它会触发一个 onFlush 事件,而不是直接处理。 真正的处理逻辑由订阅了这个事件的 CLogRouter 等路由类来完成,它们作为消费者,在事件中将日志分派给不同的目标,比如文件、邮件或数据库。这种基于事件的发布-订阅模式,将日志的收集与分发完美解耦。文章还展示了如何通过 category 参数对日志进行灵活过滤,确保只处理需要关注的信息。 作者通过阅读源码,不仅展示了如何简单地调用 `Yii::getLogger()->log()`,更揭示了框架在简单接口背后,如何通过精巧的架构实现高性能和高扩展性的日志管理。
HBase Block Cache实现机制分析
这篇讲的是HBase的Block Cache——RegionServer中负责读缓存的核心模块。它从HBase的读写内存分工切入,解释了读请求如何依次查询Memstore、BlockCache和磁盘,并最终将结果缓存的完整链路。 文章重点剖析了BlockCache的“三级缓存”设计:新访问的Block放入Single队列,多次访问则升至Multi队列,而Meta表等关键数据则放入InMemory队列。这种分级策略既保护了关键元数据,又避免了全表扫描对热点数据的冲击。默认的内存分配比例(Single:Multi:InMemory = 0.25:0.50:0.25)和LRU淘汰策略,是其在内存限制下平衡命中率的关键。 作者还深入到了HBase 0.94.1的源码层面,以`LruBlockCache`类为例,展示了缓存Block时的类型判定逻辑,以及触发后台淘汰线程`EvictionThread`的阈值条件。从整体内存布局到具体的优先级队列实现,文章清晰地拆解了HBase在保证高并发读性能时,所采用的这套精巧的缓存管理思路。
我自己研究开源项目源代码的两个重要习惯
这篇讲的是作者在长期研究开源项目源代码时,逐渐沉淀出的两个核心工作习惯:撰写代码流程分析文档,以及编写不同场景的测试用例。文章以分析 HBase 的 HMaster 和 HRegionServer 启动流程为例,具体展示了这些习惯是如何落地的。 作者并非一开始就追求完美的分析。他会在文档中按方法调用顺序梳理流程,允许自己留下未完全理解的“TODO”标记,甚至可能包含一些初期的错误理解。这份文档会随着研究的深入,经过多次反复和迭代而不断完善。关键的是,他会将这份“过程文档”提交到版本库中,既为了保存,也为了记录自己的理解历程。 文章贴出了一段真实的、略显“粗糙”的分析记录作为示例。我们可以看到,从构造 ZooKeeper 节点、生成核心组件,到复杂的初始化与分配逻辑,每一步都被尽可能细致地追踪和记录下来。这份文档的价值在“冷启动”时尤为明显——当作者时隔数月后需要重新投入某个项目时,对照着这份自己写的、充满个人注解的文档,能迅速恢复到当初的理解水平,避免了从零开始的巨大时间成本。 这两个看似“普通”的习惯,其威力在于将抽象、易逝的阅读和思考过程,转化为了具体、可版本化管理的资产。对于需要长期维护或间歇性深入的复杂代码库而言,这是一种极为高效的知识管理策略。