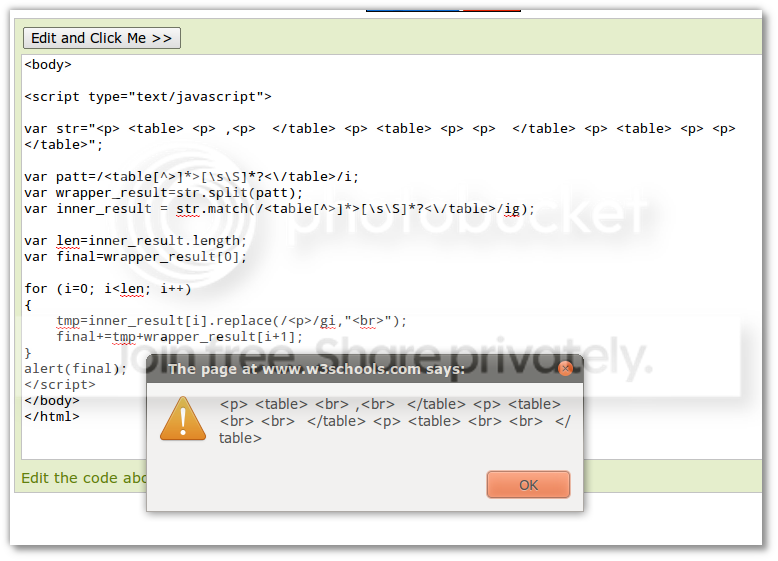
巧解 JavaScript 中的嵌套替换
这篇讲的是如何用纯正则解决JavaScript里一个挺棘手的字符串替换难题。网友wys提出了一个具体需求:如何在只用JS原生正则的前提下,完成对嵌套结构(比如多层括号或标签)的匹配与替换。这类操作常规的正则方法往往力不从心,容易出错或无法覆盖复杂情况。 文章的核心方案,是作者深入剖析了正则引擎的执行逻辑,特别是“捕获组”与“零宽断言”的组合运用。他没有推荐更复杂的解析库,而是专注于挖掘语言本身的特性。通过一种巧妙的“延时替换”或“模式迭代”思路,让正则表达式能够“看穿”一层层的嵌套,并在正确的层级执行替换操作,既保证了准确性,又兼顾了性能。 最巧妙的地方在于,整个解法优雅地绕过了正则表达式通常无法匹配“任意嵌套”结构的理论限制。作者的思路为处理这类层级文本提供了轻量级的新视角,展示在熟悉工具底层原理后,能激发多少创造性用法。
本机暂存